
Dernièrement, j’ai rencontré plusieurs soucis sur mon serveur dédié qui héberge (entre autres) ce blog.
Aujourd’hui, je vous propose de voir comment j’ai réussi à remettre rapidement mon serveur en ligne, en le réinstallant intégralement, et en changeant d’OS.
Un drame en 3 actes
Durant la nuit, à 2h du matin le 8, mon serveur a redémarré suite à un kernel panic. Arbre qui cache souvent la forêt, le kernel panic est une erreur grave que le système n’a pas réussi à empêcher et qui a eu trop d’impact pour qu’il maintienne sa stabilité. Pour les amateurs de Windows, nous pourrions comparer ça à un écran bleu (BSOD).
Le 17, je me suis rendu compte par hasard que mes pods Kubernetes n’avaient plus de résolution DNS externe, en creusant un peu, j’ai vu que mes deux pods coredns avaient crash, suite à un souci avec mon fichier /etc/resolv.d (que je n’avais pas touché, peut-être un effet de bord de mon kernel panic)
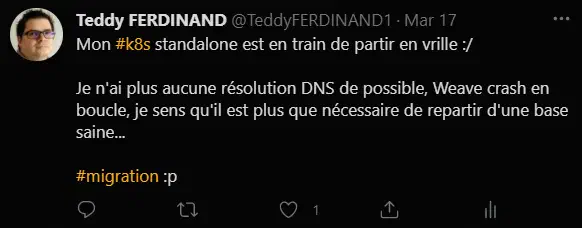
J’ai fini par réussir à redémarrer mes pods, mais coredns n’avait plus d’accès à Internet, comme le reste de mes pods!
En continuant de creuser, il apparaît que la seule solution viable est la réinstallation complète du nœud.
Petit souci, je suis sur un Kubernetes “standalone”, en effet, je n’ai pas besoin d’un cluster en haute disponibilité pour mon usage. Pour mettre à jour le nœud, je dois le drain, donc interrompre le trafic sur mon serveur, ce qui m’embête pas mal.
Je me dis donc que je vais travailler sur un script d’installation propre pour migrer vers un autre nœud de manière transparente.
C’était sans compter que mon serveur allait continuer à me faire des blagues! le 18 au soir, mon serveur Kubernetes est tombé, et je n’arrivais plus à le remettre en ligne, il crashait en boucle au démarrage.
Après une bascule sur un nœud k3s créé chez sur une machine virtuelle sur mon propre PC, j’ai réinstallé entièrement le serveur from scratch, comme nous allons le voir.
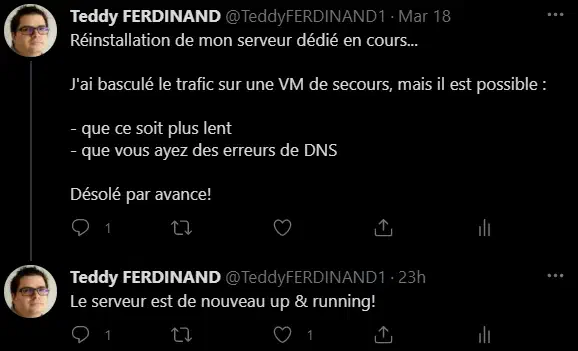
30 min pile entre ces deux messages!
Revoir mes besoins
Même si cela a été plus vite que je l’avais prévu, j’avais aussi prévu de revoir mes besoins pour migrer depuis Kubernetes qui était clairement trop “lourd” à gérer pour moi sur un seul nœud.
À titre d’exemple, mon serveur était en version… 1.12 vu que je ne pouvais pas l’arrêter pour le mettre à jour! (oui, j’ai honte)
Je me suis donc dit qu’il fallait que j’aie une solution plus simple à mettre à jour et plus légère en termes de ressource, car je n’ai pas d’énormes besoins.
Mon cahier des charges étant de :
- Déployer facilement des conteneurs
- Gérer les cycles de vie de mon application (notamment les montées de versions et rollback)
- Gérer le redémarrage automatique en cas de crash d’un conteneur
J’ai donc étudié plusieurs solutions :
- Docker solo
- Docker compose
- Podman
- K3s
Les deux premiers ont été éliminés directement, en effet, bien qu’il soit simple de déployer des conteneurs et faire ses montées de version, le redémarrage automatique est possible, mais nécessite des scripts externes, augmentant donc le coût du MCO (Maintien en Condition Opérationnelle).
Podman et K3s étaient donc les deux solutions que j’avais face à moi, et je dois avouer que j’ai choisi par “fainéantise” : venant de K8s, tous mes manifestes de déploiement étaient déjà compatibles avec K3s. De plus, je maitrisais plus l’écosystème associé.
De plus K3s à plusieurs avantages dans mon cas :
- Kubernetes conçut pour fonctionner en standalone
- Montée de version du nœud possible à chaud
- Très léger en ressource
Faciliter le déploiement et les mises à jour
L’un des autres objectifs que je m’étais fixé était aussi de simplifier autant que possible mes déploiements et mes montées de version. Le but premier étant d’avoir un code me permettant de reconstruire facilement mon infrastructure en cas d’anomalie majeure.
J’ai donc choisi d’écrire des playbooks Ansible pour répondre à ce besoin.
Ansible, qu’est-ce que c’est ?
Ansible est un configuration manager, à l’instar de Chef ou Puppet par exemple.
C’est un produit open source, qui après avoir été soutenu par RedHat, appartient maintenant à ladite entreprise.
Ansible fonctionne en mode “agentless”, c’est-à-dire qu’il n’est pas nécessaire de déployer un agent sur les nœuds à piloter. Ansible fonctionne en python et nécessite python sur la machine cible.
L’intérêt premier de ce type d’outil est surtout que l’on décrit ce que l’on veut faire plutôt que le scripter (autant que possible). Cela permet donc d’avoir un script qui peut facilement passer d’un système d’exploitation à un autre, Ansible s’occupant de l’interpréter et d’adapter les commandes en conséquence.
De plus, c’est un logiciel extensible via les modules communautaires ou que l’on peut créer soit même facilement.
Ansible est un outil que j’ai utilisé durant des années et que je maitrise donc. Il est souvent utilisé en duo avec Terraform, l’un gérant l’infrastructure, le second gérant le provisionning de celle-ci.
Le déploiement
Petit disclaimer avant tout : le déploiement que vous allez voir ci-dessous n’est pas mon déploiement complet, mais un extrait de mon infrastructure pour vous donner une idée du fonctionnement de base d’Ansible dans ce cas de figure. Comme souvent sur ce blog, l’idée est que vous puissiez appréhender et assimiler le fonctionnement de l’outil pour vous l’approprier. Le choix d’Ansible pour tout piloter n’est peut-être pas le meilleur (Helm aurait pu gérer certains points), mais c’est celui que j’ai fait pour mon cas.
Le départ et la cible
J’ai donc relancé une réinstallation complète de mon serveur depuis le manager Kimsufi (OVH). Comme je l’ai évoqué plus haut, j’en ai aussi profité pour migrer de CentOs à Debian 10, qui reste mon premier OS, et celui sur lequel je me sens le plus à l’aise. À noter que la réinstallation complète de l’OS a pris 15 minutes (avec le formatage, partionnement, redémarrages, etc.), ce qui est plutôt rapide pour une machine physique!
La cible, je l’avais déjà en tête :

K3s en remplacement de K8s, Traefik en front et mes pods en backend. Petite différence aussi par rapport à mon installation précédente, je suis maintenant derrière CloudFlare, ce qui implique certains ajustements sur mes IngressRoute Traefik.
L’idée est donc de repartir d’un serveur “vierge” (enfin presque) et de faire mon déploiement dessus.
Les scripts
Vous pouvez retrouver l’intégralité des scripts sur GitHub :
Je ne décrirais pas l’ensemble des scripts et templates ci-dessous, donc n’hésitez pas à aller voir le repository directement!
Le bootstrap
Avant tout, je veux déployer les prérequis de base sur mon serveur.
- name: Install prerequisites
apt:
name:
- python3-pip
- curl
- git
state: latest
- name: Install openshift package (k8s ansible module)
pip:
name:
- openshift
- awscli
- awscli_plugin_endpoint
- name: Deploy backup script
template:
src: backup.sh.j2
dest: /home/backup.sh
mode: 0700
- name: Create backup crontab
ansible.builtin.cron:
name: "Kubernetes content backup"
minute: "0"
hour: "2"
job: "/home/backup.sh"
- name: Create AWS directory
file:
path: /root/.aws
mode: '0700'
state: directory
- name: Deploy AWS credentials
template:
src: aws_credentials.j2
dest: /root/.aws/credentials
mode: 0600
- name: Deploy AWS configs
template:
src: aws_config.j2
dest: /root/.aws/config
mode: 0600
Nous avons donc :
- L’installation via apt de pip (pour Python3), curl et git : si les paquets sont déjà là, il ne se passera rien. Le state latest permet de s’assurer que le paquet est mis à jour à chaque lancement du script Ansible.
- L’installation du package python openshift : ce paquet est nécessaire pour piloter Kubernetes depuis Ansible, le paquet est en effet compatible avec Kubernetes et Openshift.
- L’installation du CLI AWS et d’une extension pour pousser ailleurs que sur Amazon S3
- Ensuite, je déploie un micro script de backup (qui fait un gros tgz poussé sur scaleway toutes les nuits) et j’active un cron associé
- Enfin, je déploie la configuration pour le cli AWS, exploité pour pousser sur Scaleway
L’installation de K3s
- name: "Download K3S"
get_url:
url: https://get.k3s.io
dest: "{{k3s_directory}}/k3s_installer.sh"
mode: 0700
tags:
- full_install
- name: "Start k3s"
shell:
cmd: "export INSTALL_K3S_EXEC=\"--no-deploy=traefik --no-deploy servicelb\" && \
export INSTALL_K3S_VERSION=\"{{k3s_version}}\" && \
sh {{k3s_directory}}/k3s_installer.sh"
tags:
- full_install
- name: Create KubeConfig directory
file:
path: /root/.kube
mode: '0700'
state: directory
tags:
- full_install
- name: Copy K3S configuration
copy:
src: /etc/rancher/k3s/k3s.yaml
remote_src: yes
dest: ~/.kube/config
tags:
- full_install
Ici, rien de très original :
- Je télécharge le script d’installation officiel que je copie vers mon dossier d’installation, puis je le lance en lui indiquant je ne veux pas Traefik, je préfère en effet le piloter moi-même
- ensuite, je copie la configuration de K3s vers le répertoire “standard” de Kubernetes par défaut, ce qui me permet d’exploiter d’autres outils comme K9s de manière transparente
Comme vous pouvez le voir, il y a un tag “full_install” sur chacune des tâches, je reviendrais dessus.
Enfin j’installe Traefik et mes backends :
- name: Wait for node to be ready
shell: "kubectl get nodes"
register: nodes
until:
- '" Ready " in nodes.stdout'
retries: 60
delay: 5
- name: Create deployment root path
file:
path: "{{deployment_root_path}}"
mode: '0700'
state: directory
- name: Install Traefik
include_role:
name: traefik
vars:
deploy_name: traefik
version: "{{traefik_version}}"
pilot_token: "{{traefik_pilot_token}}"
- name: Install Ghost
include_role:
name: ghost
vars:
deploy_name: "ghost-{{ghosts.deploy_name}}"
version: "{{ghost_version}}"
base_path: "{{ghosts.base_path}}"
rule_priority: "{{ghosts.rule_priority}}"
record_list:
"{{ghosts.record_list}}"
loop:
"{{ghost_installs}}"
loop_control:
loop_var: ghosts
- name: Install Commento
include_role:
name: commento
vars:
deploy_name: commento
version: "{{commento_app_version}}"
version_db: "{{commento_db_version}}"
rule_priority: 1
base_path: ""
record_list:
- commento.tferdinand.net
- La première tâche s’assure que mon K3s est bien en statut “Ready” avant de faire la moindre action, en effet, il lui faut une quinzaine de secondes à démarrer et je ne veux pas faire planter mon script parce que le nœud n’est pas prêt à recevoir du trafic
- Ensuite, je crée un répertoire pour recevoir mes configurations et contenus de mes applications, j’aime bien avec les manifestes Kubernetes dans le cas où je voudrais débug, ainsi chaque application aura son propre répertoire, ce qui simplifie la navigation
- Enfin, j’installe mes Ghost et Commento. Comme vous pouvez le voir, comme se base sur une “loop”, cela permet d’installer toutes mes instances avec le même code en prenant en compte leurs différences. De plus j’utilise un attribut “loop_control”, cela me permet de modifier le nom de la variable de la boucle par défaut, car j’ai une boucle dans le rôle que j’invoque et je me retrouve sinon avec une réinitialisation de ma variable en cours de route, ce qui provoque des fonctionnements anormaux
À propos des rôles Ansible
Comme vous pouvez le voir dans le code ci-dessus, j’invoque des rôles pour faire mes installations. Les rôles Ansible permettent de factoriser certaines commandes très facilement en permettant de les exploiter de manière similaire à des fonctions.
Il existe plusieurs moyens d’importer et utiliser des rôles :
- Depuis Ansible Galaxy : galaxy.ansible.com
- Depuis un gestionnaire de version public ou privé
- Localement dans votre répertoire Ansible
Les rôles permettent ainsi de standardiser des installations. Par exemple, en entreprise, on peut imaginer un rôle “install_nginx” qui permet d’installer un serveur Nginx de manière identique sur tous les serveurs.
Les rôles peuvent s’utiliser de deux manières :
- Dans le header Ansible, ils seront donc invoqués avant la moindre action
- En exploitant un “include_role” dans le code, qui permet de l’invoquer où l’on veut. Cette solution est de loin la plus flexible. Par défaut Ansible cherchera toujours les rôles dans le répertoire “./roles/”
Pour créer un nouveau rôle, il suffit d’invoquer la commande ansible-galaxy init qui permettra de créer la structure de base des rôles.
ted@debian:/tmp$ ansible-galaxy init test-role
ted@debian:/tmp$ tree test-role/
test-role/
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── README.md
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml
Pour en savoir plus sur les rôles, je vous invite à voir la documentation officielle :
L’installation de Traefik
Revenons à notre installation, commençons par Traefik.
L’installation est en fait assez basique grâce à la facilité qu’apporte Ansible.
- name: Create traefik deployment path
file:
path: "{{item}}"
mode: '0700'
state: directory
loop:
- "{{deployment_root_path}}/{{deploy_name}}"
- "{{deployment_root_path}}/{{deploy_name}}/content/"
- "{{deployment_root_path}}/{{deploy_name}}/content/certs"
- name: Create Kubernetes templates
template:
src: "{{item}}.yml.j2"
dest: "{{deployment_root_path}}/{{deploy_name}}/{{item}}.yml"
loop:
"{{template_files}}"
register: deployment_changes
- name: Delete existing Traefik (Port binding)
k8s:
src: "{{deployment_root_path}}/{{deploy_name}}/deployment.yml"
state: absent
when: deployment_changes.changed
- name: Deploy Kubernetes objects
k8s:
src: "{{deployment_root_path}}/{{deploy_name}}/{{item}}.yml"
state: present
loop:
"{{template_files}}"
when: deployment_changes.changed
- La première action crée mon répertoire de base pour Traefik, comme je l’ai dit plus haut, c’est un confort que j’aime avoir
- Ensuite, je crée mes manifestes de déploiement en me basant sur des templates (plus d’infos en dessous)
- Si un template a été modifié, je détruis mon pod Traefik existant. En effet, le port étant déjà bind (trick réseau pour exposer Traefik), mon nouveau pod reste en standby sans que le port soit libéré en amont. Dans les faits, cela se manifeste par une indisponibilité de quelques secondes, uniquement quand Traefik monte de version
- Enfin, je déploie l’ensemble de mes manifestes
Les templates Jinja
Ansible exploite la bibliothèque de templating Jinja2. Cela permet d’utiliser des variables valorisées à la volée dans les templates.
Jinja a aussi des fonctionnalités avancées comme les boucles par exemple (un exemple est disponible plus bas dans ce billet).
kind: Deployment
apiVersion: apps/v1
metadata:
name: {{deploy_name}}
namespace: {{namespace}}
labels:
k8s-app: {{deploy_name}}
spec:
replicas: 1
selector:
matchLabels:
k8s-app: {{deploy_name}}
template:
metadata:
labels:
k8s-app: {{deploy_name}}
name: {{deploy_name}}
spec:
hostNetwork: true # workaround
serviceAccountName: {{deploy_name}}
terminationGracePeriodSeconds: 60
containers:
- image: {{image}}:{{version}}
name: {{deploy_name}}
volumeMounts:
- mountPath: "/cert/"
name: cert
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
- name: traefik
containerPort: 8080
args:
- --providers.kubernetescrd
- --entrypoints.web.address=:80
- --entrypoints.websecure.address=:443
- --certificatesresolvers.le.acme.email={{master_mail_address}}
- --certificatesresolvers.le.acme.storage=/cert/acme.json
- --certificatesResolvers.le.acme.httpChallenge.entryPoint=web
- --pilot.token={{pilot_token}}
- --accesslog=true
- --accesslog.fields.headers.defaultmode=keep
- --accesslog.fields.headers.names.User-Agent=keep
volumes:
- name: cert
hostPath:
path: {{deployment_root_path}}/{{deploy_name}}/content/certs/
Voici par exemple le deployment de Traefik en mode template.
Je ne vais pas revenir sur l’installation de Traefik, qui est très proche de ce que j’avais déjà décrit dans un de mes anciens billets :
Installation de Ghost et Commento
Je réunis ici les deux installations qui sont similaires.
Concernant Commento, j’avais décrit la méthode d’installation il y a quelque temps :

Pour Ghost, l’installation est assez simple. En effet, Ghost est une image docker standalone qui exploite une base de données sqlite intégrée dans l’image.
Deux petits points d’attention dans les templates, en effet mon rôle prends l’ensemble des record DNS qui pointent vers l’instance en entrée, car :
- L’ensemble des record DNS est déclaré au niveau de l’IngressRoute pour Traefik
- Le premier record est déclaré pour la “base URL” de Ghost
Comment ça se manifeste?
Au niveau de l’IngressRoute, cela signifie une boucle en Jinja :
match: ({% for host in record_list %}HostHeader(`{{host}}`) {{ " || " if not loop.last else "" }}{% endfor %}) && PathPrefix(`{{base_path}}/`)
Ce qui me permet de construire à la volée l’ensemble des record DNS pour mon IngressRoute.
Côté Ghost, je prends toujours le premier record. Jinja sait accéder aux listes via leurs indexes :
value: https://{{record_list.0}}{{base_path}}/
C’est là qu’on voit la puissance de la templatisation, la moindre modification est prise en compte à tous les niveaux de manière simple et cohérente.
Lancer le tout
Installer Ansible
Déjà, je vais avoir besoin d’Ansible. Deux choix possibles :
- Je l’installe sur mon poste personnel (ce que j’ai fait)
- Je l’installe sur le serveur dédié et je lance Ansible en local
Les deux solutions sont complètement fonctionnelles et dépendent de ce que vous préférez.
Ansible fonctionne en Python, il est possible de l’installer via le gestionnaire de paquet de votre distribution, néanmoins, ce n’est pas forcément ce que je vous recommande.
À titre d’exemple, sur une Debian 10 fraîche, Ansible s’installe en version 2.7 depuis apt. Cette version date … d’octobre 2018. Depuis pip (l’installeur Python), j’ai bien récupéré la version 2.10 qui date de septembre 2020.
Pour la connexion distante, il est possible d’envoyer un login/mot de passe à Ansible, mais ce n’est clairement pas ce que je vous recommande. Ansible sait lire une clé SSH pour faire sa connexion de manière sécurisée.
Lancer le playbook
Premier lancement
Une fois Ansible installé, je n’ai plus qu’à me mettre dans mon répertoire contenant mon playbook principal et lancer le tout
ansible-playbook site.yml -i hosts
Le fichier hosts que j’ai passé en paramètre contient le nom de mon host et son login de connexion.
Mises à jour
Lorsque je fais mes mises à jour, j’ai un tag “full_install” (dont j’ai parlé plus tôt) prévu pour éviter de relancer certaines tâches qui pourraient avoir un impact sur la disponibilité de mon cluster.
Pour ignorer ces tâches, j’ai juste à l’indiquer au lancement de mon playbook :
ansible-playbook site.yml -i hosts --skip-tags full_install
Pour terminer ce long billet
Je n’ai pas abordé un point, l’un des points qui m’a permis de restaurer rapidement le nœud est aussi que j’ai des backups très réguliers (quotidiennement), et que j’ai pu restaurer l’ensemble des données d’un nœud à l’autre.
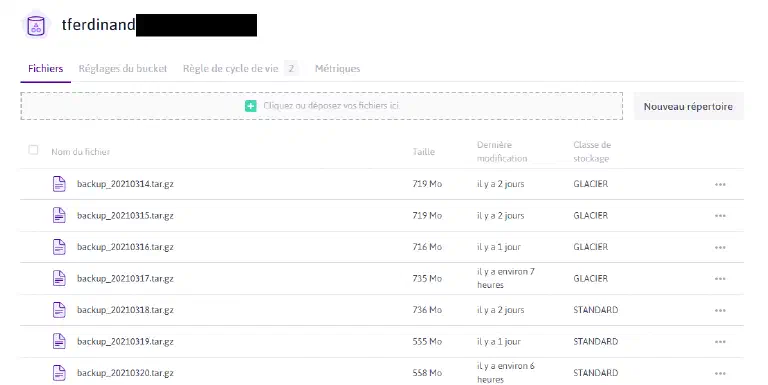
J’ai fait un peu de ménage aussi suite à l’incident :)
C’est un point que j’aborderais surement dans un prochain billet.
Concernant le choix d’Ansible, il est complètement arbitraire et un script Shell aurait sans doute fait le boulot. Ansible permet toutefois de faire que peut de scripting à part entière et de décrire les actions que l’on souhaite faire. De plus, le playbook est de fait compatible avec de nombreuses plateformes sans faire d’ajustements, Ansible le gérant pour nous.
Mon incident permet aussi de rappeler l’importance de scripter et automatiser le maximum d’actions pour qu’un crash soit le moins impactant possible. Dans mon cas, revenir en ligne en repartant de zéro en 30 minutes est un énorme plus.