
Mise à jour le 22/12/2021
Ce contenu a été mis à jour le 22/12/2021 pour pointer vers la version 2.5.5 de Traefik Proxy et Kubernetes 1.20
Il y a quelques semaines, je vous ai proposé un article expliquant la migration de Traefik 1 à Traefik 2. Je vous propose cette fois d’aborder un point crucial dans la mise en place d’une application, son monitoring.
Cet article explique comment j’ai mis en place mon dashboarding, il n’explique en aucun cas du dashboarding “entreprise” devant être plus fiable et complet sur certains points.
Durant cet article, je vais vous expliquer comment créer de manière très basique ce type de dashboard.

Technologies utilisées
Pour mettre en place ce dashboard, j’ai utilisé trois applications distinctes:
- ElasticSearch : ElasticSearch est un produit permettant d’indexer et rechercher des données, il est souvent utilisé dans des stacks ELK (ElasticSearch LogStash Kibana) pour du logging ou en stand alone en tant que moteur de recherche.
- FileBeat : FileBeat est un extracteur de logs léger créé par Elastic.co, éditeur d’ElasticSearch, son modèle est adapté aux containers. A noter que FileBeat peut aussi tourner en DaemonSet standalone pour extraire les logs d’un cluster Kubernetes complet.
- Grafana : Grafana permet de créer des dashboards a partir de sources de données multiples, et notamment ElasticSearch, utilisé ici.
1ère étape : Mise en place d’ElasticSearch
Dans le modèle que je vous propose, ElasticSearch va servir à stocker et indexer nos logs. Nous allons donc déployer ElasticSearch dans un pod pour l’exploiter ensuite. Nous créons donc le fichier de description suivant :
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.5.1
imagePullPolicy: Always
ports:
- containerPort: 9200 # Port de requête
- containerPort: 9300 # Port d'administration
env:
- name: discovery.type
value: single-node # Indique à ElasticSearch de fonctionner en mono noeud
resources:
limits:
cpu: "0.5"
memory: "2048Mi" # Ram minimal requise
---
kind: Service
apiVersion: v1
metadata:
labels:
app: elasticsearch
name: elasticsearch
spec:
type: ClusterIP
ports:
- port: 9200
name: http
- port: 9300
name: http2
selector:
app: elasticsearch
Comme indiqué, en appliquant ce dernier, nous allons déployer :
- Un pod contenant ElasticSearch en mono noeud
- Un service permettant d’exposer les port de requête et d’administration d’ElasticSearch
Information importante - Environnement de production :
Dans un environnement de production, en entreprise, on prendra en compte les données suivantes pour créer notre cluster ElasticSearch :
- Fonctionner minimum avec 3 noeuds
- Activer du stockage persistant : Pour ma part je ne considère pas ces données comme critiques, en entreprise on choisira de persister les données
- Activer l’authentification sur ElasticSearch
Vous pouvez retrouver ces informations sur le site officiel.
2ème étape : Mise en place d’un sidecar avec FileBeat et configuration de Traefik
Dans cette seconde étape, nous allons :
- Configurer Traefik pour qu’il écrive ses accesslogs dans /var/log/traefik/access.log
- Deployer FileBeat avec le module Traefik, qui va lui permettre de mappé nativement les champs des logs
- Créer un emptyDir qui nous servira de répertoire d’échange entre nos deux containers dans le pod
Je ne vais pas revenir sur l’installation de Traefik, que j’avais décrit dans mon article précédent. De manière simple, mon pod Traefik tourne dans un namespace dédié, et dans un deployment.
Nous allons donc modifier ce deployment pour ajouter notre second container ainsi que notre répertoire d’échange.
apiVersion: apps/v1
kind: Deployment
metadata:
name: traefik-ingress-controller
namespace: traefik
labels:
k8s-app: traefik-ingress-lb
spec:
replicas: 1
selector:
matchLabels:
k8s-app: traefik-ingress-lb
template:
metadata:
labels:
k8s-app: traefik-ingress-lb
name: traefik-ingress-lb
spec:
hostNetwork: true
serviceAccountName: traefik-ingress-controller
terminationGracePeriodSeconds: 60
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- image: traefik:v2.5.5
name: traefik-ingress-lb
imagePullPolicy: Always
volumeMounts:
- mountPath: "/var/log/traefik"
name: logs
- mountPath: "/cert/"
name: cert
resources:
requests:
cpu: 100m
memory: 20Mi
args:
- --providers.kubernetescrd
- --accesslog=true
- --accesslog.filepath=/var/log/traefik/access.log
- --accesslog.fields.headers.defaultmode=keep
- --entrypoints.web.address=:80
- --entrypoints.websecure.address=:443
- --certificatesresolvers.le.acme.email=masuperadressemail@monmail.com
- --certificatesresolvers.le.acme.storage=/cert/acme.json
- --certificatesResolvers.le.acme.httpChallenge.entryPoint=web
ports:
- name: web
containerPort: 80
- name: websecure
containerPort: 443
- name: admin
containerPort: 8080
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.5.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch.default
- name: ELASTICSEARCH_PORT
value: "9200"
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: logs
mountPath: /var/log/traefik
readOnly: true
volumes:
- name: logs
emptyDir: {}
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
- name: cert
hostPath:
path: /home/kube/traefik/certs/
type: Directory
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: traefik
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
filebeat.modules:
- module: traefik
access:
enabled: true
Dans ce bloc de code, nous retrouvons donc :
- Lignes 38 à 40 : Ajout des paramètres de lancement à Traefik pour activer les accesslog, les stocker dans /var/log/traefik/access.log et garder les headers dans les logs (qui sont droppés par défaut)
- Ligne 27 et 28 : Ajout du point de montage décrit plus bas, qui permet d’avoir un répertoire d’échange entre nos deux containers
- Ligne 53 à 81 : Création de notre container exécutant FileBeat, auquel on indique son fichier de configuration, les paramètres du endpoint ElasticSearch et les points de montage nécessaires
- Ligne 83 et 84 : Le volume emptyDir créé pour échanger entre nos deux containers au sein du pod
- Ligne 89 à 92: Répertoire persistant sur l’hôte, qui permet à FileBeat de stocker ses données, et notamment les pointeurs indiquant les fichiers déjà traités
- Ligne 100 à 114 : Le fichier de configuration de filebeat, qui indique l’output, ElasticSearch, et d’activer le module Traefik
Une fois que nous appliquons ce fichier de description, nous avons donc traefik qui génère des logs qui sont envoyé vers ElasticSearch toutes les 30 secondes (configuration par défaut du module Traefik de FileBeat).
3ème étape : Déploiement de Grafana
Maintenant que nous extrayons et stockons nos accesslogs, nous allons maintenant déployer Grafana, qui nous permettra de les restituer.
En prérequis, j’ai créé sur mon hôte un répertoire “/home/kube/grafana/data” qui me servira à persister les données de Grafana, et notamment les dashboards.
Encore une fois, nous créons donc un fichier de description pour Kubernetes, contenant les informations suivantes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
labels:
app: grafana
spec:
replicas: 1
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
volumeMounts:
- name: grafana-data-storage
mountPath: /var/lib/grafana
image: grafana/grafana:6.5.2
imagePullPolicy: Always
ports:
- containerPort: 3000
env:
- name: GF_INSTALL_PLUGINS
value: "grafana-worldmap-panel 0.2.1,grafana-piechart-panel 1.3.9"
resources:
limits:
cpu: "0.5"
memory: "512Mi"
volumes:
- name: grafana-data-storage
hostPath:
path: /home/kube/grafana/data
type: Directory
---
kind: Service
apiVersion: v1
metadata:
labels:
app: grafana
name: grafana
spec:
type: ClusterIP
ports:
- port: 3000
name: http
selector:
app: grafana
Nous pouvons donc voir dans ce code :
- Le déploiement de Grafana
- L’installation de plugins complémentaires : WorldMap Panel (permettant d’avoir une map avec les points) et PieChart Panel, permettant d’avoir diagramme “camembert”
- La création et l’utilisation du volume persistant
- La création d’un service permettant de l’exposer via Traefik, non décrite ici car identique à mon article précédent
4ème étape : Configurer Grafana pour se connecter à ElasticSearch
Une fois que notre Grafana est déployé, nous pouvons donc nous connecter dessus avec le super couple login/password : admin/admin…
Nous créons ensuite un mot de passe fort pour Grafana.
Maintenant nous pouvons ajouter notre première source de données : ElasticSearch, que nous allons configurer comme ainsi :
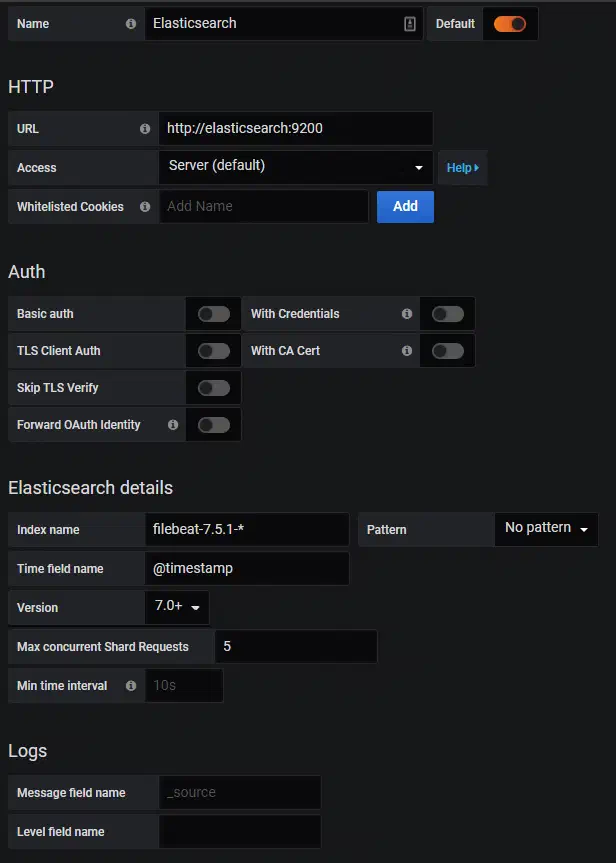
Avec cette configuration, nous allons :
- Connecter Grafana à ElasticSearch via le service créé précédemment
- Indiquer l’index name par defaut de filebeat
- Indiquer qu’il s’agit d’un ElasticSearch en version 7
En allant ensuite sur “Explore” et en cliquant sur “Logs” en haut, vous devriez maintenant voir vos logs Traefik.

Pour terminer
Maintenant que nous pouvons exploiter les accesslogs de Traefik, il est assez facile de les extraire pour en faire un dashboard comme je me le suis fait.
A noter que pour requêter ElasticSearch, il est nécessaire de le faire via le langage Lucene, j’utilise pour ma part une cheat sheet disponible ici.
Comme indiqué précédemment, le but de ce billet est simplement de vous décrire la méthode d’installation que j’ai utilisé, elle n’est sans doute pas parfaite, et il convient à vous de l’adapter à vos besoins.