
Le cloud apparaît comme un Eldorado pour beaucoup d’entreprises: déploiement plus simple des applications, réduction des coûts, utilisation de technologies innovantes, autant d’avantage qu’Amazon fait miroiter devant ses potentiels clients, mais est-ce si simple ?
AWS, et le cloud de manière plus générale, peut être un excellent levier sur les points cités précédemment, néanmoins il est assez facile d’y perdre des plumes. Dans cet article, je vais lister ce qui, pour moi, me semble les erreurs à éviter.
Think Different
Je ne suis pas fan d’Apple, mais j’aime beaucoup ce slogan. Aller dans AWS nécessite de penser différemment son infrastructure. La politique du lift and shift est rarement payante.
Outre le fait qu’il est nécessaire de s’adapter à certains paradigmes d’Amazon, il est aussi nécessaire de former ses équipes à penser autrement les infrastructures, dans un univers où beaucoup de données ne sont pas persistantes, comment créer des infrastructures performantes ?
Avoir un outillage adapté au déploiement
Amazon permet de livrer très facilement des nouvelles applications, ou version applicatives, néanmoins, si l’on veut éviter de tout piloter à la main, le principal intérêt du cloud est que tout est API. Cela signifie donc que les déploiements peuvent être entièrement automatisés via les outils adaptés.
A ce point, deux solutions, soit vous possédez déjà un outillage performant, que vous pouvez connecter à Amazon, soit vous vous orientez vers des outils adaptés.
Je considère qu’il faut à minima 2 outils complémentaires pour piloter de manière sereine un déploiement Amazon.
Dans un premier temps, il est nécessaire d’avoir un outillage d’infrastructure as code, ce dernier permet de décrire le déploiement voulu via des scripts. C’est ce qui permet d’utiliser les outils de versionning classique comme Git par exemple, l’infrastructure devient ainsi un élément versionnable, de la même manière que la moindre de vos applications.
De ce côté, je vois à minima 2 outils adaptés à ce besoin sur AWS :

- CloudFormation (lien) : L’outil AWS pour faire de l’AWS. L’avantage premier est qu’il est entièrement intégré à Amazon. Il est maintenu à jour par AWS, et ne nécessite aucune infrastructure pour fonctionner, il n’a aucun coût, autre que celui des éléments qu’il déploie. Utiliser CloudFormation permet aussi de profiter du support d’AWS sur les déploiements.

- Terraform (lien) : Outil d’infra as code open source, avec une communauté grandissante. HashiCorp est un éditeur spécialisé dans le déploiement continu. L’avantage principal de Terraform est le multicloud, il est possible de déployer en parallèle une infrastructure sur plusieurs cloud, et même on premise sur du VMWare par exemple. Contrairement à CloudFormation, Terraform à par contre besoin d’une infrastructure dédiée pour fonctionner.
Ensuite, il est très utile d’avoir une IHM, pour suivre ces déploiements ainsi que pouvoir les automatiser, par exemple lorsque qu’une nouvelle version applicative est disponible. Pour cela, la meilleure solution reste, selon moi, Jenkins, d’autant plus que l’application est souvent déjà présente en entreprise.

- Jenkins (lien) : Jenkins est un serveur d’automatisation open source. Il possède une énorme communauté qui contribue à son amélioration continue. Il permet ainsi de déclencher automatiquement des traitements sur certains événements ainsi que suivre et piloter des actions depuis une IHM centralisée. Pour les workload demandant de la charge, il peut aussi fonctionner dans un modèle master/slaves.
Il est complètement possible d’aller vers Amazon sans ces outils, néanmoins, il faut être conscient que cela complexifie énormément plus les déploiements, ainsi que le suivi des infrastructures déployées.
Se poser les bonnes questions sur son application
Aller dans le cloud nécessite aussi de se poser les bonnes questions pour optimiser sont déploiement :
- Mon application subit-elle une charge constante ?
- Mon application a-t-elle besoin de fonctionner en 24/7?
- Mon application peut-elle évoluer (ou ai-je le budget nécessaire pour ça)?
Ces questions permettent de concevoir l’architecture la plus adaptée, et la moins onéreuse.
La question de la charge des machines et fonctionnement 24/7
Amazon permet de déployer des infrastructures élastiques. Dans les faits, qu’y gagne-t-on ?
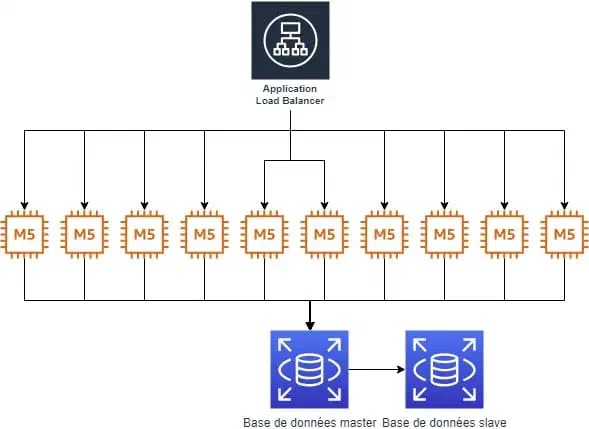
Admettons que je veuille déployer une infrastructure pour un site web classique, à savoir : un load balancer, plusieurs backends et une base de données, le tout en haute disponibilité.
De même, partons du principe que je sais que chaque serveur applicatif peut supporter 150 connections/seconde, et j’ai des variations sur le nombre d’utilisateurs qui vont de 100 connections/secondes à 1500 connections/seconde.
Si l’on suit le modèle on premise, on va donc provisionner une architecture pouvant supporter 1500 connections par seconde.
Ce qui donne quelque chose comme ci dessous (j’ai choisi arbitrairement des instances m5.large):
Coût global : 1092$ mensuel
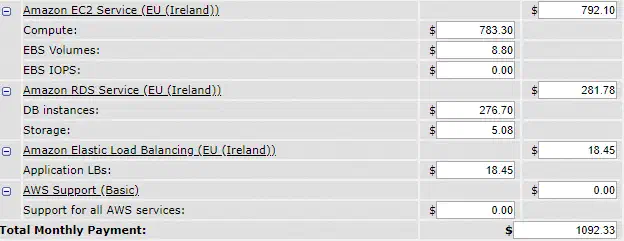
Mon application tiendra la charge, par contre, je ne comprends pas trop ce que je gagne à aller dans Amazon là…
C’est normal, si on suit cet exemple, nos ressources tournent régulièrement à moins de 20% de leur performances, par contre, on paie 100% de leur coût.
Dans le graphique ci dessous, j’ai indiqué (de manière tout aussi arbitraire) le nombre de connections, ainsi que le nombre de serveurs associés nécessaires.

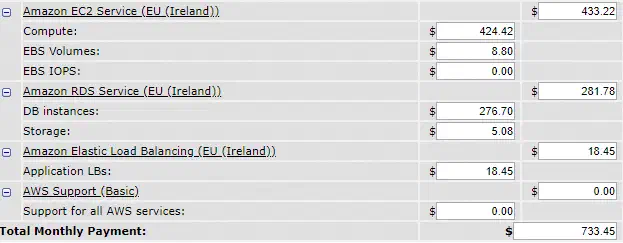
On peut observer que très souvent nous n’avons pas besoin des 10 machines actives. C’est à ce moment là que rentre en ligne de compte l’utilisation d’autoscaling groups. En passant par des autoscaling group, l’idée est de coller au plus prêt du besoin, en démarrant et arrêtant automatiquement des machines sous certaines conditions. En refaisant la même estimation, de manière très simpliste (sans prendre en compte le temps de démarrage/arrêt des machines par exemple), cela représente une économie de plus de 30% !
Penser FinOps autant que possible
Le FinOps consiste à optimiser ses coût, mais pas simplement en étant avare au moindre coût qui semble élevé, mais en ayant une visibilité complète de ces derniers. Comment faire ?
Utiliser des tags
Sur Amazon, il est possible de tagger ses machines pour les filtrer, mais ces tags peuvent aussi être exploités dans Cost explorer, qui permet de suivre les coût sur Amazon. L’intérêt est de savoir directement les projet associés à chaque infrastructure ainsi que les coûts de ces derniers.
Mutualiser les ressources
Chaque projet n’a peut être pas besoin d’être complètement autonome, et certaines ressources peuvent sans doute être partagée. Par exemple, il n’est pas forcément nécessaire d’avoir le support entreprise sur tous vos comptes AWS. De même, certains ressources bien que non payantes, peuvent être aisément mutualisées, comme les security group et les VPC par exemple, simplifiant par la même occasion les coût de MCO.
Se faire accompagner
AWS est un environnement très intéressant, mais comme je le dis souvent : “Sur Amazon, il y 300 manières de faire la même chose, toutes ne sont pas adaptées”. Petit souci, pour connaître la solution adaptée, il faut avoir assez de recul pour connaître les alternatives. La montée en compétence sur Amazon est longue, d’autant plus qu’une grande partie du travail consiste à faire de la veille technologique, au vu du nombre d’annonces faites quasiment quotidiennement.
Ce post est fini, il n’a pas pour but d’être exhaustif, mais simplement de mettre en avant ce que j’ai appris de mon expérience sur le cloud Amazon.