
Lorsque l’on doit communiquer avec des services tiers, des APIs sont souvent mises en place pour simplifier l’échange d’information.
Très souvent, en parallèle de ces dernières, on peut trouver des SDK, fourni par l’éditeur ou bien en open source.
Aujourd’hui, nous allons voir pourquoi l’utilisation des SDK est souvent à préférer à celles des API au travers d’un exemple simple : AWS et son SDK Boto3.
Le choix d’AWS est arbitraire, tout autant que Boto3, simplement parce que ce sont des technologies que je maîtrise, mais cet exemple est transposable à beaucoup de fournisseurs et langages de programmations différents. Les codes indiqués dans ce billet n’ont pas été testés et sont simplement indiqués à titre d’illustration.
AWS au pays des APIs
AWS s’est entièrement construit autour de ses APIs, c’est l’un de ses piliers depuis sa création. Il est possible d’interroger toutes les ressources ou bien d’envoyer des commandes depuis ces dernières.
Ce sont ces APIs qui sont utilisées lorsque vous êtes connectés à la console AWS par exemple.

Un des exemples d’appel API AWS
Dans l’image ci-dessus, on peut voir les requêtes envoyées par mon navigateur lorsque je suis sur la console AWS.
Cette requête renvoie par exemple des informations de ce format :
{"requestId":"86104bcc-2e26-4059-be5b-2fe91be5ece1","reservations":[]}
À ce moment, on pourrait être tenté d’utiliser directement ces APIs pour faire des requêtes AWS, mais ce n’est pas si simple.
Les limites de l’utilisation de l’API
Commençons par un sujet simple : je veux récupérer la liste des instances.
Rien de plus simple! J’ai une API dédiée à ça chez AWS.
Maintenant, je vais me mettre dans le cas d’une production. L’une de mes priorités va donc être que mon script soit le plus résilient possible et puisse s’adapter à des anomalies.
Donc, je vais scripter mon appel. Pour l’exemple disons que je vais faire du bash en utilisant le très populaire curl.
Dans tous les exemples ci-dessous, AUTHPARAMS est à remplacer avec vos credentials comme décrits sur ce lien.
Si je suis la documentation, je me retrouve donc avec :
curl "https://ec2.amazonaws.com/?Action=DescribeInstances&MaxResults=10&AUTHPARAMS"
Maintenant, je vais vouloir tester que ma commande a fonctionné, donc je rajoute un test du code retour :
curl "https://ec2.amazonaws.com/?Action=DescribeInstances&MaxResults=10&AUTHPARAMS"
if [ $? -ne 0 ]
then
echo "Une erreur est survenue"
exit 1
fi
C’est mieux, mais en fait, je teste le retour du binaire curl, ce qui reste utile, mais n’est pas suffisant. Il faut aussi que je teste le code retour de ma requête HTTP.
http_code=$(curl "https://ec2.amazonaws.com/?Action=DescribeInstances&MaxResults=10&AUTHPARAMS" -o /tmp/request --silent -w "{%http_code}")
if [ $? -ne 0 ]
then
echo "Une erreur est survenue"
exit 1
fi
if [ "${http_code}" != "200" ]
then
echo "Le code retour HTTP n'est pas 200"
exit 2
fi
Il s’agit là d’une des solutions possibles avec curl, il y en a beaucoup d’autres.
On commence à voir un souci :
- Mon résultat est maintenant dans un fichier plat
- Je dois multiplier les checks
- Je dois gérer ma query string d’authentification
Mais continuons!
Pour le moment, cela reste simple. Mais pour autant, est-ce que je veux traiter pareil un code retour 403 (Forbidden) qu’un code retour 404 (Not found) qu’un code retour 500 (Internal server error).
Les trois cas m’indiquent 3 informations importantes :
- Le 403 m’indique que mon authentification est erronée ou doit être rafraichie
- Le 404 m’indique sans doute une erreur dans mon appel (ou un appel hors range)
- Le 500 m’indique une erreur du côté d’AWS pour traiter ma requête
Du coup, je me retrouve maintenant avec un code de ce type :
http_code=$(curl "https://ec2.amazonaws.com/?Action=DescribeInstances&MaxResults=10&AUTHPARAMS" -o /tmp/request --silent -w "{%http_code}")
if [ $? -ne 0 ]
then
echo "Une erreur est survenue"
exit 1
fi
case ${http_code} in
"200") echo "OK, on continue";;
"403") echo "Erreur d'authentification"
refresh_creds;;
"404") echo "Non trouvé"
exit 2;;
"500") echo "Erreur de traitement AWS"
retry_command;;
*) echo "Code retour inattendu"
exit 3
esac
Mon code devient déjà plus fourni, pour un appel assez simple. De plus, je ne couvre que les cas que je connais. Il est possible qu’Amazon renvoie d’autre message en fonction des API ou réponses.
Continuons.
Maintenant que j’ai testé que mes codes retour curl et http sont cohérent, je veux traiter le résultat, je vais donc parser ce résultat, dans mon cas, il est maintenant dans un fichier plat.
http_code=$(curl "https://ec2.amazonaws.com/?Action=DescribeInstances&MaxResults=10&AUTHPARAMS" -o /tmp/request --silent -w "{%http_code}")
if [ $? -ne 0 ]
then
echo "Une erreur est survenue"
exit 1
fi
case ${http_code} in
"200") echo "OK, on continue";;
"403") echo "Erreur d'authentification"
refresh_creds;;
"404") echo "Non trouvé"
exit 2;;
"500") echo "Erreur de traitement AWS"
retry_command;;
*) echo "Code retour inattendu"
exit 3
esac
echo "Réponse AWS : $(cat /tmp/request | jq)"
Mais que se passe-t-il si :
- Mon fichier a été écrasé en cours de route
- Mon résultat est dans un format inattendu
etc.
Je dois encore ajouter des tests de retours.
Je pense que vous avez compris où je veux en venir, en exploitant l’API “brute”, on obtient des résultats, mais si on veut couvrir un maximum de cas, on arrive vite à un script très fourni.
Pourquoi les SDK nous aident?
Gestion de l’authentification
Déjà, parlons du premier sujet que j’ai volontairement éludé dans la première partie : l’authentification.
Si je veux gérer dans mes appels API l’authentification, j’arrive vite à des appels lourds, l’authentification AWS étant assez conséquente. De plus, je dois gérer le rafraichissement de mes clés d’API (dans le cas d’un rôle AWS, elles expirent au bout d’une heure par défaut).
AWS met à disposition une authentification passant par ses fichiers de configurations exploités notamment par sa CLI.
L’avantage pour nous, c’est que ces fichiers sont aussi gérés par les différents SDK d’AWS de manière transparente. C’est-à-dire que sans rien spécifier, le profil par défaut (ou celui précisé par la variable d’environnement AWS_PROFILE) est déjà chargé et exploitable par mon SDK.
Le SDK : La bibliothèque qui cache l’API
L’autre avantage d’utiliser un SDK est qu’il va vous permettre de “masquer” une partie des contrôles que nous devions faire nous-mêmes afin de mieux gérer les cas d’erreurs.
Si je reprends mon code précédent en python, j’obtiens donc ceci pour la base sans tests :
import boto3
ec2 = boto3.client('ec2')
response = client.describe_instances()
Comme on peut le voir, le code est déjà très simpliste par rapport à son équivalent en API.
L’avantage premier, comme décrit plus haut est que la gestion de l’authentification est transparente, même s’il est possible de la gérer ou surcharger dans le script.
Maintenant, ajoutons de la gestion d’erreur :
import boto3
import botocore
import logging
ec2 = boto3.client('ec2')
try:
response = ec2.describe_instances()
except botocore.exceptions.ParamValidationError as error:
raise ValueError(f'Erreur de paramètre : {error} !')
except Exception as error:
raise SystemError(f'Erreur inattendue : {error} !')
print(response)
Comme on peut le voir, je n’ai plus de notion de code retour de mon exécution, mais simplement du traitement de l’éventuelle exception levée lors de mon appel.
En réalité, voici ce qui s’est passé au travers de ce simple appel :
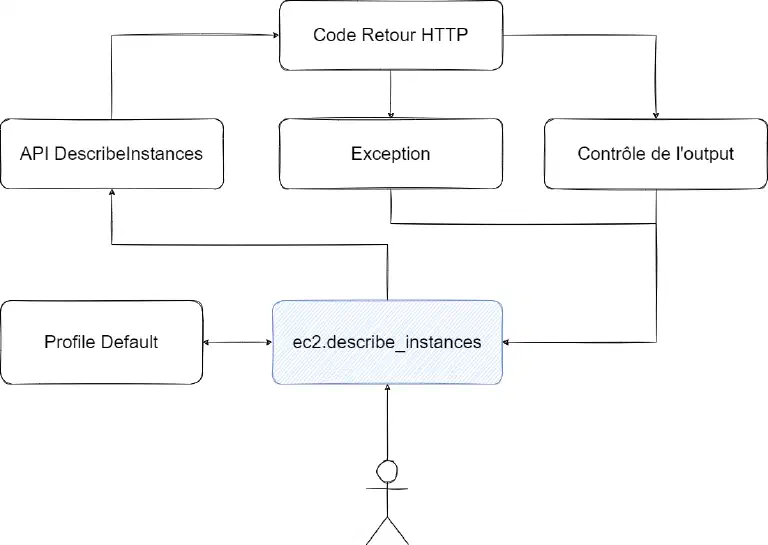
Lorsque j’ai appelé ma fonction ec2.describe_instances(), j’ai en fait :
- Récupéré mes informations de connexion
- Appelé l’API, car le SDK exploite l’API en bas niveau
- Contrôlé le code retour
- Contrôlé le contenu retourné pour voir s’il était cohérent avec l’attendu
- Renvoyé le contenu ou l’erreur dans un format directement exploitable
L’avantage premier est que l’ensemble de ces informations a été récupéré et traité de manière complètement transparente pour moi. Pour information, en mettant le niveau de log en débug, en python, vous pouvez voir tous les appels API effectués vers AWS.
En conclusion : Le SDK gagne par KO
Ici, il n’y a clairement pas photo, le SDK simplifie grandement l’utilisation de l’API et le pilotage global d’AWS. C’est quelque chose qu’on retrouve très souvent. J’aurais pu tout autant citer Twitter, Keycloak ou même Datadog pour lesquels j’aurais fait les mêmes constats.
Parfois le SDK brut est très efficace, parfois son exploitation packagée via des outils tiers comme Terraform ou Ansible l’est.
L’idée principale est de se dire que le SDK va piloter beaucoup de traitement de manière transparente.
Attention toutefois, pour moi, il reste important de comprendre ce que fait le SDK. Par exemple, j’ai déjà eu des cas d’anomalie sur Terraform pour déployer une infrastructure Amazon que j’ai réussi à comprendre uniquement en descendant au niveau des appels API effectué par Terraform au travers du SDK Go AWS.