
Lorsque l’on veut utiliser le CLI AWS pour piloter ses ressources en ligne de commande, la solution la plus simple est de passer par des access keys. Ces clés APIs, gérées par AWS permettent de s’authentifier simplement en passant par un utilisateur IAM.
Toutefois, quand on veut centraliser en dehors d’AWS ses utilisateurs, la tâche se gâte ! Aujourd’hui, je vais vous expliquer comment j’ai mis en place une gestion de credentials AWS temporaires avec une fédération externe à AWS, et pourquoi.
Mon cas d’usage
Le cas d’usage que je vais vous présenter est assez standard. Dans une entreprise, on a choisi de centraliser de manière externe à AWS les utilisateurs. On peut aisément imaginer un ADFS, Okta ou une solution open source comme Keycloak pour fédérer nos utilisateurs d’enteprise.
Au travers de cette fédération, je peux accéder à la console web et consommer des rôles AWS, qui me permettent d’avoir les droits dont j’ai besoin pour travailler.
Toutefois, lorsque je passe en ligne de commande, ce n’est plus aussi simple. Nativement, il n’est pas possible de se connecter à AWS en utilisant une fédération externe en ligne de commande.
Le service AWS SSO fait le job, et permet aussi d’obtenir des accès temporaires en ligne de commande, mais dans mon cas, on voulait une seule centralisation, en dehors d’AWS.
Exemple de credentials temporaires via AWS SSO - Source : Blog officiel
Ce cas est assez courant. L’authentification étant une brique critique de l’infrastructure, on va très souvent essayer de la découpler de nos services. Ainsi si AWS venait à être défaillant (ce qui n’est pas très courant, je vous l’accorde), mon authentification fonctionne toujours, je ne suis pas dépendant d’une ressource externe à mon entreprise. Dans l’autre sens, si mon entreprise perdait son lien réseau (ce qui peut parfois arriver, même en redondé… pour l’avoir vécu), j’ai toujours mon authentification pour mes applications internes, ce qui réduit l’impact.
En plus de ce découplage, je veux que mes utilisateurs aient des credentials purement temporaires. Pourquoi ?
- Je veux gérer les cycles arrivées/départs de l’entreprise de manière simple et centralisée (ma fédération)
- Si mes clés “leaks”, par exemple dans un repository public, l’impact est très limité, puisqu’elles expirent vite
- Je ne veux pas que mes utilisateurs créent des IAM users partout, avec des clés qui ne tournent pas assez et que je devrai gérer à leur départ
Toutefois, je veux aussi que cet accès temporaire soit le plus transparent possible pour mes utilisateurs, et fonctionne de manière simple dans des scripts et programmes avec les SDK AWS.
Les profils AWS
Les profils AWS permettent d’effectuer de manière simple des actions dans un environnement multicompte AWS.
En ajoutant le paramètre “–profile nom” ou en utilisant la variable d’environnement “AWS_PROFILE”, je peux facilement utiliser des accès à des comptes AWS spécifiques.
Par exemple, en faisant ainsi, je peux utiliser S3 sur mon profil “dev”
aws s3 ls --profile dev
Ce profil est défini dans un fichier ~/.aws/credentials (car c’est un accès par access keys dans ce cas)
[dev]
aws_access_key_id=AKIACLEDEXEMPLE
aws_secret_access_key=JESUISUNESUPERCLEDEXEMPLE
Ainsi, lorsque j’ai invoqué le profile AWS, j’ai été au préalable identifié via ces tokens
Dynamiser ses profils
Depuis quelques mois, il est possible de rajouter un nouveau format de paramètres à ses profils AWS. En effet, en lieu et place des clés ci-dessus, il est possible de dire à la CLI d’utiliser un external process. Comme son nom l’indique, cela signifie que l’on demande à la ligne de commande de récupérer ses informations d’identification en passant par une ressource externe.
De là, vous allez me dire “OK, mais c’est quoi l’intérêt ?”.
L’intérêt, c’est que l’on peut dès lors utiliser un script pour renvoyer notre clé. Vous voyez où je veux en venir? Notre script va gérer notre authentification, et renvoyer les informations nécessaires à AWS.
Je peux donc configurer mon fichier de configuration de cette manière à la place de la configuration précédente :
[dev]
credential_process = monsupersts.py --env dev --username teddy.ferdinand
De là, lorsque j’invoquerai mon profil, AWS exécutera mon script.
Comment se passe l’authentification ?
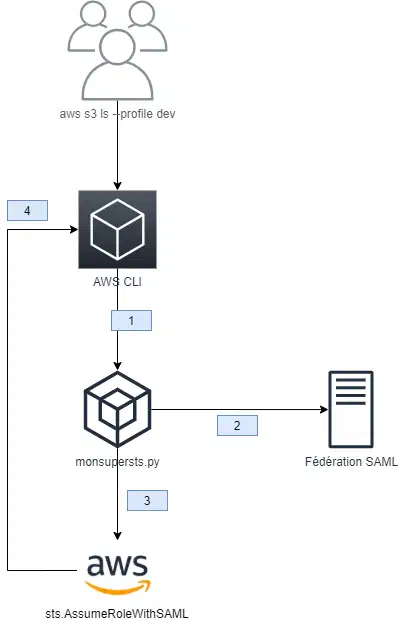
Lorsque je fais ma commande, il se passe en réalité plusieurs choses :
Le CLI détecte ma configuration et invoque mon script que j’ai défini en external process
Mon script m’authentifie, il se charge de me demander éventuellement mes informations : login, mot de passe, MFA, etc. Dans mon exemple, la fédération est en SAML, mais on pourrait imaginer de l’OIDC
L’assertion SAML de mon authentification me permet de faire un AssumeRoleWithSAML sur AWS, qui me fournit donc un JSON de credentials de rôle (décrit plus bas)
Je renvoie ce JSON à mon CLI, qui peut invoquer ma commande S3
Ces quatre étapes se déroulent de manière complètement transparente pour l’utilisateur en très peu de temps (potentiellement quelques millisecondes). Pourtant, j’ai atteint mon objectif initial, des informations d’authentification temporaires et centralisées sur ma fédération.
Le JSON demandé est standard, il s’agit du même format que celui renvoyé par l’AssumeRoleWithSAML :
{
"Version": 1,
"AccessKeyId": "ASIATEMPACCESSKEY",
"SecretAccessKey": "MASUPERSECRETKEYTEMPORAIRE",
"SessionToken": "MONTOKENTEMPORAIRETOUTAUSSIGENIAL",
"Expiration": "2020-10-07T08:23:00+0000"
}
Comme vous pouvez le voir, mon token a une date d’expiration définie. De plus, la présence de la clé “SessionToken” rappelle qu’il s’agit d’une clé temporaire. On peut aussi noter que la clé générée ainsi commence en ASIA (clé temporaire) au lieu d’AKIA (clé classique).
Gérer son cache
En plus du mécanisme de base, il est nécessaire de gérer son cache si on veut éviter que nos utilisateurs veuillent nous tuer aient à taper leur mot de passe à chaque commande invoquée.
Dans mon cas, j’ai choisi simplement de stocker le JSON localement sur le poste utilisateur et le renvoyer tant que la date de validité n’est pas dépassée.
On peut considérer que ce JSON ne contient pas de données sensibles (en tout cas pas plus sensible que des clés en clair dans un fichier de configuration), d’autant plus que sa validité est très limitée, par défaut les clés sont utilisables une heure.
AWS indique bien sur sa documentation qu’il s’agit de la responsabilité de l’utilisateur de gérer son cache :

En conclusion
Comme vous pouvez le voir, il est assez simple de passer par des mécanismes complètement personnalisés pour s’authentifier en ligne de commande sur Amazon. Cette utilisation permet de se passer d’information de connexion valide très (trop ?) longtemps et simplifie la gestion de ses utilisateurs, permettant une centralisation complète.
Toutefois, elle ajoute une couche supplémentaire à maintenir, et il faut être conscient que cette brique devient critique et qu’AWS n’apportera aucun support dessus.
Concernant le script, je ne vous l’ai pas fourni, car il est propre à chaque mécanisme d’authentification dans une entreprise, le modèle reste de toute façon relativement simple. Le but de ce billet était avant tout d’expliquer ce mécanisme d’authentification AWS qui n’est pas forcément très mis en avant.
Pour aller plus loin, il est aussi possible d’utiliser un coffre fort pour stocker ses informations et l’invoquer directement, comme avec aws-vault, qui a un mode prévu à cet effet.
Pour ma part, en tant que security guy, je dois avouer que je suis plutôt fan de ce modèle qui permet d’allier une gouvernance forte des utilisateurs, un accès restreint dans le temps et une utilisation transparente via les profils.