
Le 10 mars au matin, un incendie se déclarait dans un datacenter d’OVH, à Strasbourg.
Cet incendie a eu un énorme impact, brulant un datacenter au complet, et en endommageant un autre.
Voici donc mon analyse à chaud de la situation et de la réaction sur les réseaux sociaux.
Petit rappel : OVH c’est quoi ?
Commençons par le commencement. OVH (rebrandée OVH Cloud depuis peu) est une entreprise spécialisée dans l’hébergement informatique de manière très large :
- Location de serveur dédié
- Location de VPS (Virtual Private Server = Machine virtuelle)
- Hébergement de serveur : vous pouvez héberger votre propre serveur chez OVH
- Cloud computing
- Hébergement via OpenStack
C’est une entreprise française, créée en 1999 par Octave Klaba.
C’est aujourd’hui l’un des leaders mondiaux de l’hébergement :
- Plus de 30 datacenters
- Plusieurs centaines de milliers de serveurs physiques
- Plus de 2000 employés
À titre d’information, ce site est actuellement hébergé chez OVH, sur la gamme “low cost” : un KimSufi (Nom commercial : Serveur KS-10 — Intel i5-2300 — 16 GB DDR3 1333 MHz — 2 To SATA).
Quel est l’impact de l’incendie ?
L’impact de l’incendie est assez impressionnant, le datacenter SBG2 a été réduit en cendre, et 35 % de SBG1 a brulé avec.
Les deux autres datacenters du site ont visiblement été épargnés, mais sont actuellement hors ligne suite à l’intervention des pompiers. Ils doivent être remis en service en début de semaine prochaine.
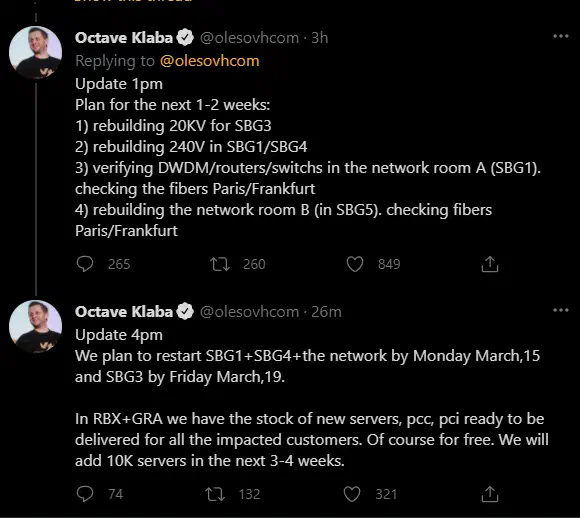
Pour comparaison, voici un avant/après (Images issues d’un tweet de @Karlesnine)


Les réactions sur Twitter
Sur Twitter j’ai vu nombre de réactions, que je vais vous décrire ici en vous donnant mon point de vue.
Mon serveur est inaccessible, c’est inadmissible/pas sérieux/bande d’amateurs (rayez la mention inutile)
Tweets que l’on peut voir en réponse à la déclaration de l’incident, que l’on peut aussi assimiler avec “quand est-ce que les serveurs reviennent en ligne ?”.
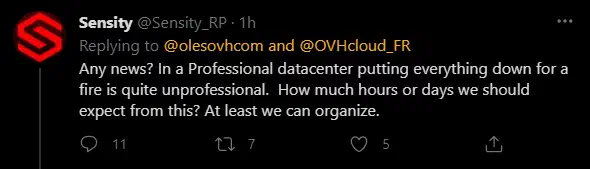
Clairement lorsqu’un incendie aussi grave est en cours, ma priorité n’est clairement pas de savoir si mon serveur va revenir de suite, mais plutôt de m’inquiéter pour les êtres humains, vous savez ces trucs sur lesquels on hurle :
- Les employés d’OVH
- Les pompiers
Je suis choqué de voir que certains n’ont absolument aucun sens des priorités lors d’incidents aussi graves.
J’ai perdu toutes mes données !
Si vous avez perdu toutes vos données à cause de la perte du datacenter, cela signifie :
- Que ces données ne sont pas importantes
- Que vous n’avez pas sécurisé des données importantes
Dans les deux cas, le seul responsable… c’est vous !
C’est même indiqué noir sur blanc dans les conditions de vente que vous (client) avez acceptées !

Tout comme je l’avais déjà dit dans un de mes précédents billets sur AWS, c’est à l’utilisateur de déterminer le risque d’une indisponibilité et de faire le nécessaire pour la combler :

La redondance/sauvegarde ça coûte cher !
On m’a opposé le souci de coût pour les associations/petites entreprises, pour moi ce n’est pas un frein, stocker des données “à froid” ne coûte pas énormément d’argent, c’est moi même ce que j’utilise.
Si besoin une sauvegarde manuelle régulière peut même être suffisante. Pour ma part, je sauvegarde mon serveur de manière hebdomadaire, car je n’ai pas de données que je juge critiques dessus.
Pour éviter de mettre toutes ses billes dans le même panier, on peut utiliser par exemple (attention, les coûts varient avec les coûts de transferts) :
- C14 chez Scaleway, pour rester sur un cloud souverain : à partir de 0,002 € HT/Go/mois
- S3 Glacier chez AWS, le leader du cloud n’a plus rien à prouver sur ce domaine : à partir de 0,004 USD par Go/mois
Faut que je migre vite chez [NOM DU CONCURRENT]
Si c’est pour reproduire les mêmes erreurs d’architecture (non-redondance, pas de sauvegarde, etc.), autant rester chez OVH.
Encore une fois, avec des sauvegardes régulières et éventuellement de la haute disponibilité multiprovider ou multisite, il n’y a pas de soucis avec l’incident du jour.
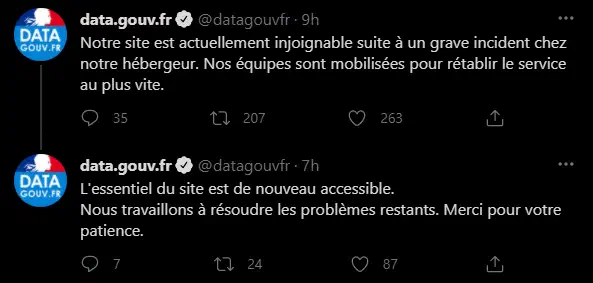
D’ailleurs, data.gouv.fr (vu qu’on aime bien taper sur les sites gouvernementaux) l’a bien prouvé, indisponible le matin même, revenu quelques heures plus tard.
OVH ne sait même pas maîtriser un incendie !
On peut aussi mettre son petit frère “OVH n’a même pas de quoi détecter un incendie”.
Soyons clair, actuellement on ne sait RIEN, mais alors rien du tout sur la cause de l’incendie et de la raison de son ampleur.
Plutôt que de tirer des conclusions hâtives, il serait sage d’attendre quelques jours/semaines que les analyses nécessaires soient faites et qu’un vrai post mortem soit disponible.
Si à ce moment-là OVH est vraiment fautif, c’est l’occasion de les critiquer, aujourd’hui nous n’avons clairement pas assez d’informations pour ça.
Mention spéciale pour les charognards
Lors d’un incident aussi grave, la concurrence a deux manières de réagir :
- Soutenir son concurrent : simple message, ressources à disposition, etc.
- Profiter de l’instant de faiblesse de son concurrent : Dire que nous on est meilleurs, et que vous devriez aller voir ailleurs.
Voici un bel exemple du second point :

Qu’on se le dise, dans ce genre de moment, montrer du respect pour son concurrent est toujours mieux :
- Cela permet de renvoyer une image bienveillante à votre communauté
- Si un jour vous avez un incident grave, les gens (et vos concurrents) seront moins durs avec vous
- Personne n’a envie de travailler avec des c… d qui se comportent comme des charognards !
Pour terminer : l’expérience est indispensable
Pour ma part, j’ai déjà subi une panne majeure de datacenter dans ma carrière :
- Transformateur électrique qui lâche
- Générateur de secours qui se met en défaut au bout de dix minutes alors qu’il avait été testé via un test de bascule une semaine plus tôt
- Liens réseau qui lâchent
Le tout en cascade en quelques minutes. L’incident ne s’est pas produit parce que nous ne l’avions pas prévu, mais parce que toutes les sécurités sont tombées en panne au même moment.
Cette expérience m’a appris beaucoup de choses sur la haute disponibilité, les bascules, l’importance des sauvegardes, etc., et je n’ai nul doute que les “victimes” du jour vont beaucoup en apprendre à leur dépend aussi.
Aller chez un provider cloud, quelqu’il soit ne vous dédouane pas de bonnes pratiques de base :
- Sauvegarder régulièrement votre contenu, la sauvegarde est une part INDISPENSABLE de n’importe quelle application
- Tester régulièrement les sauvegardes, j’ai déjà connu des restaurations qui ne marchaient pas
- Déployer votre infrastructure en infra as code autant que possible, pour qu’elle soit aisément reproductible
- Si besoin, n’hésitez pas à utiliser un autre provider cloud, pour de la haute disponibilité ou du stockage de sauvegarde
Pour finir ce billet, j’ajouterai juste que je suis de tout cœur avec les équipes d’OVH mobilisées sur cet incident qui doivent vivre des instants assez compliqués actuellement.