
Ce billet a été co-écrit par Victor Grenu. Qui travaille en tant que Cloud Architect
Introduction
Dans cette série, nous parlerons de l’émergence du mouvement DevSecOps, et plus particulièrement, quels sont les avantages de l’introduction d’une approche DevSecOps sur vos pipelines CI/CD existants.
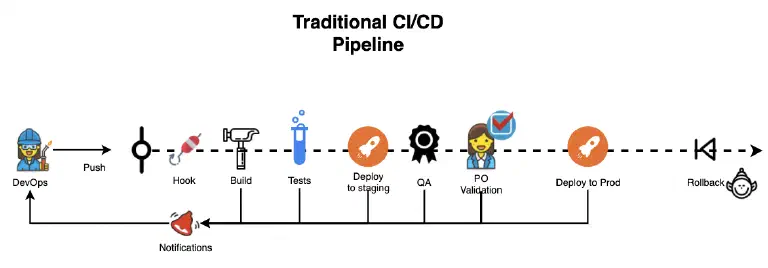
Pipeline CI/CD
Pour vous donner un peu de contexte, vous trouverez dans le diagramme ci-dessous un pipeline standard de CI/CD.
DevSecQuoi?
Le DevSecOps pourraient être définies comme un passage d’une équipe centrale de sécurité interne à l’inclusion de pratiques de sécurité dans les équipes DevOps existantes : DevSecOps
Auparavant, la sécurité d’un produit ou d’une application était évaluée à la fin du cycle de vie du projet, avec un “go/no-go” de l’équipe de sécurité, parfois avec un test de sécurité comme pentest, ou une révision du code de sécurité.
Aujourd’hui, la sécurité est devenue le travail de base, tout le monde est responsable, cela ne peut pas être que le problème du RSSI ou des équipes de sécurité. Chacun a un rôle à jouer dans ce domaine. Avec l’agilité apportée par le DevOps et les cycles rapides, la réduction du Time-to-Market, nous devons faire plus vite, mais en toute sécurité.
Lorsque les équipes DevSecOps construisent un produit, elles doivent ajouter des contrôles de sécurité à chaque couche.
Comme le changement introduit par le DevOps il y a quelques années, le mouvement DevSecOps est un changement de mentalité. Ils doivent être responsables de ce qu’ils livrent.
Tour d’horizon de la sécurité des CI/CD
Dépôt de code source
Commits signés (Authentification)
L’une des particularités de Git est que l’utilisateur doit nous dire qui il est. L’ajout de commits signés garantit qu’il ne se fait pas passer pour quelqu’un d’autre. En effet, chaque utilisateur dispose de sa propre clé, qu’il utilise pour signer son commit. Cette clé garantit que la validation provient de 100 % de l’utilisateur, même si le compte est compromis.
Un compte compromis doit dans ce cas avoir accès au login, au mot de passe (et au MFA qui est activée sur le compte bien sûr), et à la clé de cryptage utilisée pour signer le commit.
Comment utiliser cette fonctionnalité ?
# Activer la signature pour tous les commits
git config --global commit.gpgsign true
# Activer la signature uniquement pour le repository en cours
git config commit.gpgsign true
# Configurer votre clé GPG (en remplaçant MY_GPG_KEY par la votre)
git config --global user.signingKey MY_GPG_KEY
# Signer un seul commit
git commit -S -m your commit message
Ensuite, il suffit de push comme d’habitude pour créer un commit signé.
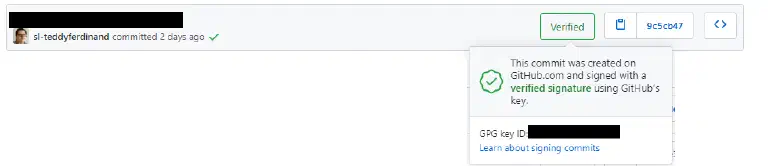
Note : L’administrateur de votre repository peut forcer l’utilisation de commits signés
Empêchez la divulgation de secrets en utilisant des pre-commit hooks
En tant que “gars de la sécurité”, l’une de nos craintes est de trouver sur un dépôt (public ou non) des credentials valides.
A noter qu’il est aussi important de traiter cette question pour les dépôts privés que pour les dépôts publics, car la plupart des attaques proviennent d’une compromission interne.
Il est possible d’utiliser des mécanismes de pré-commit pour éviter ce type de compromission. Toutefois, il faut garder à l’esprit qu’un pre-commit a lieu du côté du client et qu’il peut être contourné.
Il s’agit d’une couche de sécurité supplémentaire, mais il serait dangereux de la considérer comme fiable à 100 %. De plus, le scan de secrets ne détectera jamais 100 % de vos secrets, surtout si vous avez des credentials d’entreprise avec un format spécifique. Avoir unpre-commit hook n’évite pas une bonne culture de sécurité dans vos équipes DevOps.
L’une des solutions les plus efficaces pour y parvenir est l’utilisation de Git-secrets maintenu par AWSLabs.
Ce script peut être installé et exécuté à chaque commit afin d’éviter de pousser des secrets vers Git.
Si vous poussez par erreur le secret dans votre dépôt git, considérez qu’il est compromis et modifiez le immédiatement.
Contrôle d’accès au dépôt de code
Bien sûr, signer vos commits est une bonne pratique, mais gérer correctement vos utilisateurs en amont reste essentiel !
De quoi s’agit-il ?
Sans entrer dans les détails de chaque gestionnaire de version, quelques règles de base :
- Préférez l’utilisation du SSO, ce sera plus facile pour les utilisateurs et pour votre cycle de vie d’utilisateur.
- Avoir une politique de mots de passe forte
- Encourage l’utilisation de l’authentification multi-facteur (MFA)
- Autorisation de groupe : Utilisation de groupes d’utilisateurs pour s’assurer que les autorisations sont appliquées à tous les utilisateurs et pour éviter autant que possible les différences de droits.
- Avoir des processus automatisés d’arrivée / départ de l’entreprise en tenant compte de la suppression des comptes.
- Contrôler régulièrement les utilisateurs enregistrés
Tests de construction + tests d’intégration + tests de sécurité
Scanner de code
Lorsque vous développez vos applications, vous utilisez très certainement des bibliothèques externes, c’est quelque chose de normal et de sain, votre but n’est pas de réinventer la roue.
Cependant, ces bibliothèques sont-elles fiables ?
Nous pouvons dire “J’utilise les bibliothèques des principaux acteurs, alors ne vous inquiétez pas”. C’est une grave erreur.
Il y a des tonnes d’exemples de sociétés qui ont fourni des librairies qui ont ensuite été compromises, y compris les GAFAM, et il est normal, le principe de sécurité est que les mécanismes de défense évoluent constamment pour garder une longueur d’avance sur les pirates.
C’est pourquoi il est important d’avoir l’hygiène de la mise à jour des bibliothèques tierces lors du développement d’une application. Garder une trace de tous les CVE alors que vous avez parfois des dizaines ou des centaines d’applications est une tâche impossible à faire à la main.
Vous me direz que je ne peux pas suivre toute les CVE liés à ma pile technique. Vous avez raison, il existe des outils pour vous aider, comme SecAlerts. Il vous suffit de choisir un logiciel pour être averti des nouveaux CVE liés. Plutôt utile.
Il existe quelques règles simples pour limiter la dette technique à la découverte d’une faille:
- Limiter autant que possible les dépendances externes, en partant toujours du principe qu’aucune bibliothèque, interne ou externe, ne doit être considérée comme fiable à 100 %.
- Corrigez la version des bibliothèques utilisées, et n’utilisez pas “latest”, qui peut provoquer des dysfonctionnements inattendus.
- Produire un manifeste de version, qui facilite les controle et la liste des bibliothèques “obsolètes” qui doivent être mises à jour. Cela permet également de les centraliser dans une CMDB et de visualiser rapidement l’impact d’une CVE critique par exemplee
- Lorsque vous ajoutez une bibliothèque tierce, vérifiez son cycle de mise à jour/version pour voir si le développeur ou l’équipe de développement suit le projet de près, si une faille est découverte, cela peut être un point clé.
Pour information, GitHub et GitLab scannent automatiquement les référentiels pour faire apparaître les codes vulnérables connus.
Il est possible d’ajouter des déclencheurs sur ces scans pour les traiter automatiquement ou ouvrir des tickets aux équipes de développement.
Avoir un code à jour est un must have !
Pour vous aider sur cette étape, vous pouvez utiliser Code Inspector, développé par un de mes amis talentueux (Victor) qui travaille actuellement chez Twitter.
Gestion des secrets
La gestion des secrets est toujours une question sensible pour les demandes.
Comment gérer (par exemple) :
- Les informations de connexion à ma base de données
- Les credentials nécessaires pour le déploiement
- Les Clés API pour les communications entre applications
- Les hooks Slack
Simplifions les choses, nous mettons tout dans des variables d’environnement !
Euh… attendez une minute… Non, je vous ai dit que c’est exactement ce que nous ne voulons pas faire !
Voici malheureusement un anti-modèle que nous voyons trop souvent…
Une variable d’environnement n’est pas un stockage sécurisé.
Alors, comment faire ?
Nous utiliserons un coffre fort. Son rôle sera de stocker en toute sécurité toutes nos informations de connexion et nos clés, en limitant drastiquement les applications qui peuvent y accéder.
Le premier avantage est que les informations de connexion deviennent “volatiles” et ne sont plus stockées à côté de l’application.
Plusieurs solutions peuvent être utilisées pour y parvenir :
- AWS SSM Parameter store (chaîne sécurisée) (avec chiffrement KMS)
- AWS Secrets Manager (attention aux coûts s’il y a beaucoup d’accès !)
- HashiCorp Vault (non lié à un fournisseur de services en ligne)
- HSM : Pour l’environnement on premise, vous pouvez également utiliser la sécurité matérielle pour stocker vos clés et vos informations sensibles
- CloudHSM est également disponible sur l’AWS.
L’idée est toujours la même, un accès sécurisé aux informations de connexion.
Mais il ne suffit pas de stocker les informations de connexion en toute sécurité. Vous n’avez jamais eu d’ informations de connexion qui ont été donnés “temporairement” pour un incident, ou qui ont été récupérées par un utilisateur… ? Bon, vous ne l’avez jamais vu alors, parce qu’en réalité, c’est ce qui se fait souvent !
C’est pourquoi cette politique de stockage des mots de passe doit être couplée à une politique de rotation stricte.
Dès que les informations sont extraites dynamiquement d’un coffre-fort, il est très facile de les faire tourner régulièrement. Il ne s’agit donc plus d’un mot de passe ou d’une informations de connexion, mais plutôt d’un jeton.
Tests de sécurité
Il est également possible et recommandé de scanner régulièrement votre code et vos artefacts à l’aide des outils SAST (Static Analysis Security Testing).
Ces outils rechercheront les défauts connus de votre code et indiqueront la criticité associée.
Dans ce domaine, le leader reste GitLab CI avec les nombreux langages déjà pris en charge.
Néanmoins, d’autres solutions commencent à émerger.
En ce qui concerne l’open source, on peut penser à Reshift, qui fait un très bon travail dans ce domaine.
Quelle que soit la solution retenue, gardez à l’esprit qu’une solution SAST ne fera qu’indiquer les défauts possibles mais ne les corrigera pas nécessairement automatiquement.
Des tests de non régression sont toujours requis pour toute mise à niveau, même mineure. Une modification mineure peut parfois apporter son lot d’anomalies.
Elle peut aussi parfois entraîner une dégradation des performances, ce qui nécessite de revoir son infrastructure.
C’est tout ✋🏻, Dans la prochaine partie, nous nous concentrerons sur la partie déploiement de votre pipeline CI/CD DevSecOps.