
Résumé des épisodes précédents
Dans les deux premiers billets de cette série, nous avons vu comment créer notre bucket de base, configurer notre nom de domaine, et manipuler rapidement Hugo.
Dans ce dernier billet de la série, nous allons donc passer à l’étape manquante : le déploiement.
Automatiser le déploiement sur Scaleway
Créer un utilisateur API
Nous allons commencer par créer un utilisateur API sur la console Scaleway.
Pour cela, rendez-vous sur le menu en haut à droite, puis “Identifiants”
Cliquez ensuite sur “Générer une nouvelle clé API”, puis donnez-lui un nom.
Copiez de suite les identifiants, il ne sera pas possible de les récupérer ensuite!
Préparer la clé dans le repository
Dans votre repository Github, rendez-vous dans “Settings”, puis “Secrets”

Nous allons créer deux secrets :
AWS_ACCESS_KEY_ID: qui porte la clé publiqueAWS_SECRET_ACCESS_KEY: qui porte la clé privée
Ces secrets ne sont pas récupérables directement, à part par votre pipeline de déploiement.
Préparer la configuration S3 pour Scaleway
Scaleway exploitant le standard S3 d’AWS, nous allons utiliser la ligne de commande d’Amazon pour pousser sur S3.
Toutefois, nous aurons besoin de configurer le client pour qu’il pointe vers scaleway au lieu d’AWS.
La configuration nécessaire est décrite sur la documentation officielle de Scaleway :
Pour ma part, j’ai donc créé un répertoire aws à la racine de mon repository, qui a simplement un fichier config avec le contenu suivant :
[plugins]
cli_legacy_plugin_path = /home/runner/.local/lib/python3.8/site-packages
endpoint = awscli_plugin_endpoint
[default]
region = fr-par
s3 =
endpoint_url = https://s3.fr-par.scw.cloud
signature_version = s3v4
max_concurrent_requests = 3
max_queue_size = 1000
multipart_threshold = 5000MB
multipart_chunksize = 1000MB
s3api =
endpoint_url = https://s3.fr-par.scw.cloud
retries =
max_attempts = 20
Préparer notre pipeline Github actions
Enfin, nous allons préparer un fichier de configuration pour notre pipeline, c’est ce dernier qui se chargera de livrer chaque modification sur notre bucket.
Pour ce faire, nous allons créer le fichier .github/workflows/deploy/yml, dans lequel nous allons mettre le contenu suivant :
name: CI
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
workflow_dispatch:
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Install Hugo engine
run: sudo apt update && sudo apt install -y hugo unzip python3-pip
- name: Install Aws CLI v2
run: |
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "/tmp/awscliv2.zip"
cd /tmp
unzip awscliv2.zip
sudo ./aws/install --update
cd -
- name: Install awscli_plugin_endpoint
run: pip3 install awscli_plugin_endpoint && pip3 show awscli_plugin_endpoint
- name: copy ScaleWay AWS CLI configuration
run: |
mkdir ~/.aws
cp ./aws/config ~/.aws/config
- name: Compile items
run: hugo -D
- name: Push to Scaleway storage
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: /usr/local/bin/aws s3 sync --delete ./public/ s3://demo-hugo.tferdinand.net/
Ce fichier indique plusieurs informations :
- Nous ne voulons lancer le pipeline que lors d’un commit sur master, ou le merge d’une branche sur le master
- Nous allons utiliser une image docker Ubuntu pour effectuer le déploiement
- Nous avons un déploiement en plusieurs étapes
Concernant ces étapes nous avons donc :
- Le checkout du code : nous indiquons que nous voulons que le code de notre repository soit rapatrié (c’est mieux pour l’utiliser)
- Ensuite, nous installons via apt : Hugo, unzip, et pip. Ces derniers sont peut être déjà présents, mais ça ne coûte rien de s’en assurer
- Après, nous déployons le client AWS V2, comme le point précédent, il est peut être déjà là, mais ça ne coûte rien.
- Nous installons ensuite le plug-in nécessaire pour surcharger le endpoint S3 vers Scaleway
- Nous déployons notre configuration AWS
- Nous lançons la compilation du site avec Hugo, il nous générera les fichiers HTML statiques dans le répertoire “public”
- Enfin, nous poussons le site sur S3, l’option
--deletepermettant de supprimer les fichiers qui ne sont éventuellement plus présents
Let’s rock!
Maintenant que tout est prêt, il est temps de faire un gros push vers Github.
Si vous allez sur l’interface, dans l’onglet “actions” vous devriez voir votre pipeline tourner.
En quelques minutes, il devrait avoir fini :
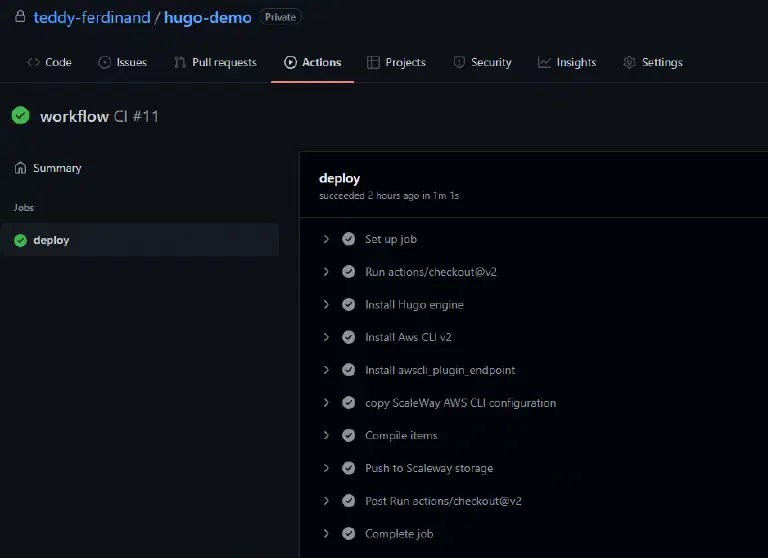
Et si vous allez sur votre bucket sur Scaleway, vos objets sont bien présents :

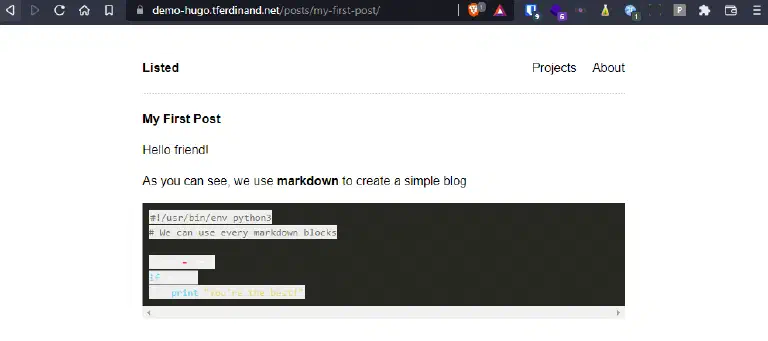
Enfin, si nous retournons sur notre record DNS que nous avions créé plus tôt, nous avons bien notre site qui s’affiche :
En conclusion
Hugo est un outil puissant
Dans ce billet, je n’ai fait que survoler Hugo. Si vous voulez en savoir plus, je vous encourage vivement à visiter la documentation du projet, qui a le mérite d’être très accessible.
Scaleway vous permet de commencer un blog sans prendre de risque
Le stockage objet de scaleway est adapté si vous voulez commencer un blog sans prendre de risque.
En effet, il ne coûte rien, et vous permet d’avoir un service de qualité sans avoir besoin de passer du temps à le maintenir en fonctionnement.
De plus, cela vous permet d’héberger vos données en France, par un acteur français!
Github simplifie les choses
J’ai fait le choix de Github pour ce billet, mais j’aurais pu aller jusqu’au Github pages, qui permettent aussi d’héberger du contenu statique. J’ai choisi de mettre Scaleway comme point final, car je voulais montrer qu’on pouvait aussi héberger en France sans avoir plus de difficultés.
Ces billets sont une base
Comme je l’ai dit plusieurs fois, ces billets sont une simple base, beaucoup de choses sont améliorables, et beaucoup de chemins alternatifs sont possibles.
Le but est simplement de montrer une solution, fonctionnelle de bout en bout.
N’hésitez pas à réagir dans les commentaires si vous voyez des points à améliorer!