
Il y a quelque temps, je vous avais parlé du tracking et des raisons pour lesquelles je tenais à ma vie privée. Dans ma conclusion, j’indiquais que le tracking utilisateur restait tout de même un outil utile pour une entreprise, à condition qu’il soit éthique et respectueux des utilisateurs.
Toutefois, très souvent, je vois que Google Analytics est utilisé par les sites sur lesquels je navigue. Ce dernier est loin (même très loin) d’être respectueux des données de vos utilisateurs. Pire! Vous permettez à Google de connaitre l’activité de votre site de bout en bout et de savoir comment mieux cibler ses publicités (entre autres).
Aujourd’hui, je vous propose donc de voir comment il est possible de faire du tracking utilisateur en faisant preuve de respect pour ce dernier.
Matomo, qu’est-ce que c’est ?
Matomo, c’est une alternative OpenSource à Google Analytics. Disponible sur GitHub, elle vous permet de déployer une application complète avec un dashboard et un système de tracking en JavaScript. Il est aussi possible de se baser sur la lecture des logs du serveur plutôt que le JavaScript.
Avoir une solution libre vous permet de connaître ses méandres, mais surtout et le gage de respect pour vos utilisateurs. Le libre porte aujourd’hui la majorité d’internet (dont ce site web).
Matomo vous permet donc d’avoir les statistiques utilisées classiquement comme (de manière non exhaustive) :
- Les pages visitées
- Les “User Agent” (OS, Navigateur, langue, etc.)
- Le taux de transformation depuis les réseaux sociaux
- Du GeoIp
- Le taux de rebond
- La durée des sessions
Basée sur le couple classique, mais efficace PHP + MySql, l’application est légère et intègre aussi des composants visant au respect de la vie privée :
- Support du header DoNotTrack, qui vous permet d’indiquer que vous ne souhaitez pas que le site web suive votre activité
- Support des contraintes RGPD (consentement éclairé), il est possible d’activer ou désactiver directement Matomo pour chaque utilisateur
- Anonymisation ou pseudoanonymisation native des données
Ainsi il est possible d’avoir des statistiques claires et complètes sans être intrusif.
À noter qu’il existe aussi une solution managée directement par Matomo, disponible sur leur site internet.
Dans le cas que je vais vous présenter aujourd’hui, nous partirons de l’image docker officielle.
Deployer Matomo dans Kubernetes
Comme d’habitude sur ce blog, je vais vous parler du déploiement dans Kubernetes, car c’est ce que j’ai sous la main et c’est devenu de plus en plus courant aujourd’hui.
Pour rappel, mon déploiement n’est pas un déploiement “prod ready” en entreprise, il ne gère pas la haute disponibilité et le scaling est catastrophique vu que la base de données est dans le même pod. Ce billet reste simplement une “démo” de ce qui est possible pour que vous puissiez l’adapter facilement à votre besoin. L’idée étant bien sûr que vous puissiez vous approprier l’outil.
Bien que le déploiement soit dans Kubernetes, il reste facilement transposable sur Docker ou Docker-compose (ou podman, ou rancher, etc.).
Voici donc le déploiement que nous allons faire, en bleu, ce sont les éléments que nous allons créer :
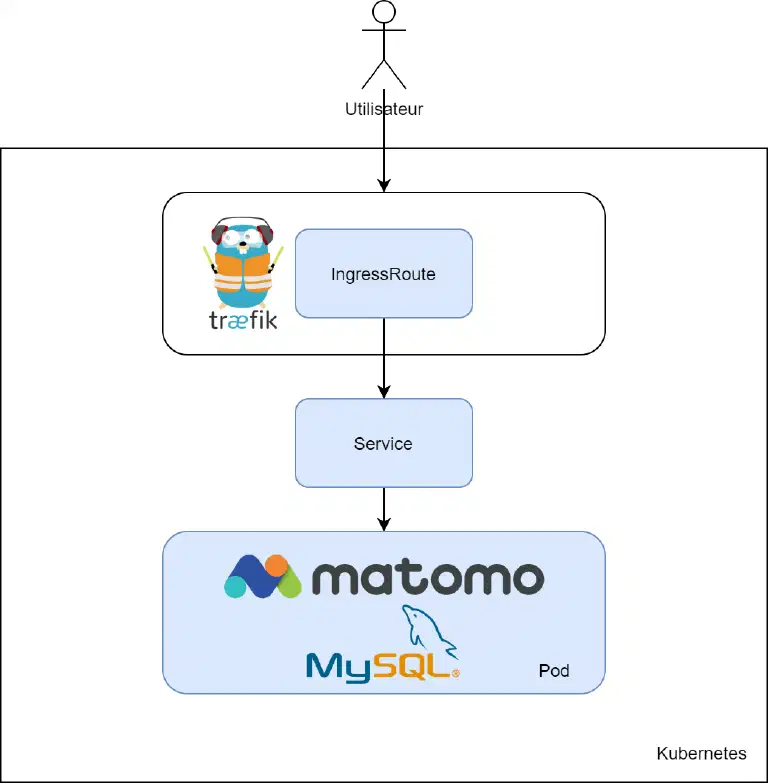
Nous allons donc avoir 3 fichiers yaml :
- Un “deployment” portant Matomo et MySql
- Un “service” permettant d’exposer Matomo
- Un IngressRoute permettant à Traefik de servir Matomo et gérer son certificat TLS
Le déploiement
Nous sommes ici sur quelque chose de très basique :
- Deux images (Matomo et MySql)
- Une configuration de la base de données (utilisateur, base par défaut, etc.)
- Du stockage persistant
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: matomo
labels:
app: matomo
spec:
replicas: 1
selector:
matchLabels:
app: matomo
template:
metadata:
labels:
app: matomo
spec:
containers:
- name: matomo
image: matomo:4.1.1-apache
imagePullPolicy: Always
ports:
- containerPort: 80
env:
- name: MATOMO_DATABASE_HOST
value: 127.0.0.1
- name: MATOMO_DATABASE_USERNAME
value: "root"
- name: MATOMO_DATABASE_PASSWORD
value: "matomo"
- name: MATOMO_DATABASE_DBNAME
value: "matomo"
volumeMounts:
- name: matomo-storage
mountPath: /var/www/html/config
- name: mysql
volumeMounts:
- name : mysql-storage
mountPath: /var/lib/mysql
image: mysql:8.0.23
imagePullPolicy: Always
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "matomo"
- name: MYSQL_DATABASE
value: "matomo"
resources:
limits:
cpu: "0.2"
memory: "512Mi"
volumes:
- name: mysql-storage
hostPath:
path: /home/kube/matomo/content/mysql
type: Directory
- name: matomo-storage
hostPath:
path: /home/kube/matomo/content/matomo
type: Directory
On retrouve donc tout d’abord le container Matomo, basé sur une image Apache.
Ce dernier a donc comme configuration :
- Un binding sur le port 80 du pod
- La configuration de la base de données. Dans mon exemple, je n’ai pas besoin de mettre un mot de passe fort, car la base est dédiée à Matomo est uniquement accessible par ce dernier.
- Un stockage persistant. Cela permet à Matomo de stocker ses configurations localement (notamment la configuration de la base de données). Cette configuration n’est pas valide pour un déploiement haute disponibilité, vu que j’exploite du stockage local
Ensuite, nous avons un second container qui porte la base de données MySql, avec comme configuration :
- Les logins et mots de passe sur la base de données
- Le binding du port 3306 à l’intérieur du pod uniquement, donc uniquement accessible par Matomo
- Un stockage persistant : Je ne veux pas perdre mes données au moindre redémarrage. Une fois de plus, cette configuration n’est pas valide pour un déploiement en haut disponibilité.
Ensuite, nous avons un service, qui va nous permettre d’exposer Matomo :
kind: Service
apiVersion: v1
metadata:
labels:
app: matomo
name: matomo
spec:
type: ClusterIP
ports:
- port: 80
name: http
selector:
app: matomo
Rien de transcendant ici, je bind simplement le port 80 de mon pod sur une ClusterIP Kubernetes.
Enfin, je déclare un IngressRoute, c’est ce dernier qui permettra à Traefik de router le trafic vers mon pod.
kind: IngressRoute
metadata:
name: matomo-tls
namespace: default
spec:
entryPoints:
- websecure
routes:
- kind: Rule
match: Host(`matomo.tferdinand.net`)
services:
- name: matomo
port: 80
middlewares:
- name: security
tls:
certResolver: le
options:
name: mytlsoption
namespace: default
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: matomo
namespace: default
spec:
entryPoints:
- web
routes:
- kind: Rule
match: Host(`matomo.tferdinand.net`)
services:
- name: matomo
port: 80
middlewares:
- name: security
- name: redirectscheme
On retrouve donc ici 2 bloc, un en http et un en https, avec une redirection automatique de l’un vers l’autre.
Ensuite, on peut voir que j’attribue donc le record DNS “matomo.tferdinand.net” à ce dernier.
Enfin, j’applique les mêmes patterns de sécurité que j’avais décrits dans un de mes anciens billets.
Je peux donc maintenant appliquer mes 3 configurations.
Configurer Matomo
Configurer le serveur
En vous connectant sur l’adresse déclarée dans Traefik, vous devriez voir l’assistant d’installation.
Ce dernier va vous guider pas à pas pour :
- Configurer votre base de données
- Configurer votre premier utilisateur administrateur
- Configurer votre premier site
Vous pouvez voir l’ensemble des étapes ci-dessous :







Intégrer le tracker js
Comme vous avez pu le voir, Matomo fonctionne via un tracker JavaScript à intégrer dans votre site Internet.
C’est ce dernier qui va interagir avec le client pour remonter les informations nécessaires.
Pour activer Matomo sur mon site, j’ai donc juste à intégrer ce code. Dans le cas de Ghost, mon blog, j’ai un paramètre prévu pour ça dans “Code injection” > “Site headers”.
En vous connectant sur l’interface de Matomo, vous devriez voir arriver du trafic, en prenant en compte que :
- Les navigateurs envoyant un header DNT (Do Not Track) n’enverront pas d’informations (comme Brave par exemple)
- Du point de vue RGPD, vous devez obtenir le consentement de l’utilisateur avant de collecter ses informations et déposer un cookie sur son poste. Matomo met à disposition un guide dédié à ce sujet (https://fr.matomo.org/docs/gdpr/).

Pour aller plus loin
Il est aussi possible, comme je l’ai évoqué plus haut, de coupler Matomo à des fichiers de logs.
Il existe en effet un script python livré dans l’image Matomo qui vous permet de faire cette action, en partant de format de logs connus, mais aussi de définir des formats personnalisés.
Pour utiliser ce script, il y a deux prérequis :
- Python 3.x
- PHP 7.x
Toutefois, l’image utilisée plus haut est bien basée sur l’image officielle PHP, comme on peut le voir sur le repository GitHub, mais n’a pas Python d’installé.
Si vous souhaitez utiliser ce script, il existe donc deux solutions :
- Créer une image custom pour ce script avec Python et PHP
- Repartir de l’image officielle en ajoutant PHP, comme ainsi
FROM matomo:4.1.1-apache
RUN apt update -y
RUN apt install -y python3
RUN apt-get purge -y --auto-remove && rm -rf /var/lib/apt/lists/*
Le script est ensuite facilement utilisable, comme indiqué dans la documentation officielle :
Concernant l’authentification, trois solutions sont possibles. Soit vous être dans l’image qui exécute l’application, et le script va pouvoir exploiter directement les fichiers de configurations et donc se connecter directement.
La seconde solution est de créer un jeton qui va vous permettre de vous authentifier et de le passer en paramètre avec le switch –token-auth, ce token peut être créé depuis l’interface de Matomo. Pour ce faire, il suffit de cliquer sur le rouage en haut à droite, puis “Sécurité” et “Créer un nouveau jeton”.

Attention, le token ne peut être récupéré qu’une seule fois, donc n’oubliez pas de le stocker dans un environnement sécurisé.
Enfin, la troisième solution, que je déconseille fortement, il est aussi possible de passer directement un login et mot de passe en ligne de commande.
Importer les logs avec un cronjob Kubernetes
Pour ma part, j’ai choisi d’importer les logs en exploitant un cronjob Kubernetes.
En effet, j’ai choisi de ne pas deployer le javascript que je trouve trop intrusif pour vous, mes visiteurs. J’ai donc opté pour l’analyse des logs bruts fournis par Traefik.
J’ai aussi choisi de ne pas utiliser l’image officielle pour ce besoin et j’exploite donc une authentification par jeton.
L’image
L’image docker que j’ai utilisé est assez basique :
FROM python:3.8.7-buster
RUN apt update\
&& apt install git \
&& git clone https://github.com/matomo-org/matomo-log-analytics.git \
&& rm -rf /var/lib/apt/lists/*
Je pars d’une image python 3.8 (car l’importeur n’est compatible qu’avec certaines versions) puis je clone le repository associé.
Vous pouvez récupérer l’image directement créée via dockerhub :
Le job
J’ai choisi de mettre à disposition mes logs Traefik dans un répertoire que je peux monter quand j’en ai besoin.
Pour en savoir plus sur la configuration des logs, je vous invite à lire mon article à ce sujet :

J’ai donc ensuite créé un cronjob Kubernetes, qui va me permettre de lire les logs à intervalle régulier pour les intégrer dans Matomo.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: matomo-importer
spec:
schedule: "5 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: matomo-importer
image: tferdinand/matomo-log-importer:1.0.0
imagePullPolicy: IfNotPresent
env:
- name: PROCESSING_DATE
value: $(date -d "1 hour ago" "+%d/%b/%Y:%H")
- name: TOKEN
value: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
- name: TRAEFIK_INGRESS_ID
value: "default-traefik-web-ui-tls-c463f039d72c55f0aca6"
- name: ID_SITE
value: 1
command:
- /bin/bash
- -c
- grep $(TRAEFIK_INGRESS_ID) /tmp/access.log | grep $(PROCESSING_DATE) > /tmp/matomo_$(ID_SITE).log; python matomo-log-analytics/import_logs.py --url=https://matomo.tferdinand.net --idsite=$(ID_SITE) --debug --token-auth $(TOKEN) --log-format-name=common /tmp/matomo_$(ID_SITE).log
volumeMounts:
- name: shared-storage
mountPath: /tmp/
restartPolicy: OnFailure
volumes:
- name: shared-storage
hostPath:
path: /home/kube/share/from_traefik
type: Directory
Je fais donc tourner cette tâche une fois par heure, pour traiter l’heure précédente.
Le “grep” que l’on voit au début me permet de sortir uniquement les logs pour le service que je veux, l’importateur de log de Matomo ne sachant pas gérer le format des logs traefik de manière plus fine.
ID_SITE me permet d’indiquer l’identifiant du site sur Matomo, par défaut 1.
Ainsi, toutes les heures, je peux suivre la fréquentation du site, le tout sans impacter mes utilisateurs. A noter qu’il est possible de descendre à la minute en ajustant les paramètres.
En conclusion
Matomo est une alternative fiable et plus respectueuse de vos utilisateurs. Il est complètement possible de l’envisager dans un environnement professionnel.
Si vous avez une nécessité de statistiques plus consistante sur votre site, il est en soi mieux pour vos utilisateurs d’utiliser cette solution plutôt que Google Analytics.
De plus, héberger vous-même la solution vous permet aussi de respecter plus facilement les contraintes liées au RGPD. L’ouverture du code vous garantissant aussi qu’aucune exploitation tierce des données n’est faite.
J’insiste aussi sur le fait que tous les sites n’ont pas forcément besoin de tracking complet, pour ma part, une simple exploitation des logs me permet de sortir des données cohérentes.